SQL
Points abordés dans cet article
Mis à jour le 22 juin 2025
L’essentiel en un clin d’œil
SQL pour l’analyse de données
- Définition : SQL (Structured Query Language) est un langage de requête permettant de manipuler des bases de données relationnelles.
- Pourquoi c’est clé : il permet d’extraire, trier, filtrer et transformer efficacement de grandes quantités de données.
- Commandes fondamentales :
SELECT,FROM,WHERE,GROUP BY,ORDER BY. - Fonctions utiles : d’agrégation (
SUM,AVG…), chaînes (LEFT,CONCAT…), date (YEAR,MONTH…). - Opérations essentielles : jointures (
INNER,LEFT…), sous-requêtes, insertion (INSERT), mise à jour (UPDATE), suppression (DELETE). - Outils associés : MySQL, PostgreSQL, SQL Server, SQLite + outils de BI comme Power BI, Tableau, et langages comme Python ou R.
- Bonnes pratiques : normalisation des bases, optimisation des requêtes, sécurisation des accès, documentation claire.

L’analyse de données est une compétence clé pour les entreprises qui cherchent à améliorer leur efficacité et leur rentabilité. SQL (Structured Query Language) est un langage de programmation utilisé pour interagir avec les bases de données relationnelles, qui sont l’un des types de bases de données les plus couramment utilisés pour stocker et gérer les données.
Dans cette introduction, nous commencerons par définir SQL et expliquer pourquoi il est important dans l’analyse de données. Nous donnerons également un aperçu du plan de l’article pour aider les lecteurs à comprendre ce qu’ils peuvent s’attendre à apprendre.
SQL est un langage de programmation utilisé pour interagir avec les bases de données relationnelles. Les bases de données relationnelles sont des bases de données structurées qui stockent les données dans des tables contenant des colonnes et des lignes. SQL permet aux utilisateurs de rechercher, d’extraire et de manipuler des données dans ces tables en utilisant des requêtes.
SQL est important dans l’analyse de données car il permet aux utilisateurs d’accéder rapidement et facilement à des données volumineuses stockées dans des bases de données. SQL est également un langage standard, ce qui signifie qu’il est largement utilisé et reconnu dans l’industrie, ce qui en fait un outil précieux pour les professionnels de l’analyse de données.
Dans cet article, nous allons examiner les bases de SQL, les fonctions SQL, la gestion des données avec SQL, l’optimisation des requêtes SQL, les outils d’analyse de données SQL et les bonnes pratiques SQL pour une analyse de données efficace.
Les bases de SQL
Maintenant que nous avons vu les éléments de base de SQL, il est temps d’explorer les bases de SQL plus en détail. Dans ce chapitre, nous allons examiner la syntaxe de base de SQL et les principales commandes SQL que vous devez connaître pour commencer à interagir avec les bases de données relationnelles.
Nous commencerons par expliquer la syntaxe de SQL, qui est assez simple et facile à apprendre. Ensuite, nous aborderons les principales commandes SQL, telles que SELECT, FROM, WHERE, GROUP BY et ORDER BY, et comment les utiliser pour extraire les données souhaitées d’une table.
En fin de compte, ce chapitre vous fournira les connaissances de base dont vous avez besoin pour interagir avec les bases de données relationnelles en utilisant SQL.
Les éléments de base de SQL (tables, colonnes, lignes)
Les éléments de base de SQL sont les tables, les colonnes et les lignes. Les tables sont des structures de données qui stockent des informations dans des colonnes et des lignes. Chaque table est constituée d’un ensemble de colonnes qui définissent les types de données que la table peut stocker, ainsi que d’un ensemble de lignes qui contiennent les données elles-mêmes.
Les colonnes d’une table définissent les différents types de données que la table peut stocker. Par exemple, une table de clients peut contenir des colonnes telles que le nom, l’adresse, le numéro de téléphone, l’adresse e-mail, etc. Chaque colonne a un nom unique et un type de données qui détermine le type de données que la colonne peut stocker, comme du texte, des nombres, des dates, etc.
Les lignes d’une table contiennent les données elles-mêmes. Chaque ligne représente un enregistrement unique dans la table. Par exemple, une table de clients peut contenir des lignes pour chaque client, avec les informations de chaque client dans les colonnes correspondantes. Les lignes ont souvent un identifiant unique appelé clé primaire qui les distingue les unes des autres.
Les tables, les colonnes et les lignes sont les éléments de base de SQL. Les utilisateurs de SQL peuvent créer de nouvelles tables, ajouter des colonnes à des tables existantes, ajouter des lignes à des tables existantes, ou extraire des données à partir de tables existantes en utilisant des requêtes SQL.
La syntaxe de SQL
La syntaxe de SQL est assez simple et facile à comprendre. En général, les requêtes SQL sont structurées en phrases qui suivent un ordre spécifique.
La commande SELECT est utilisée pour spécifier les colonnes que vous souhaitez inclure dans votre requête. La commande FROM est utilisée pour spécifier la table à partir de laquelle vous souhaitez extraire les données. La commande WHERE est utilisée pour filtrer les résultats de la requête en spécifiant des conditions. La commande GROUP BY est utilisée pour regrouper les résultats en fonction d’une colonne spécifique. Enfin, la commande ORDER BY est utilisée pour trier les résultats en fonction d’une ou plusieurs colonnes.
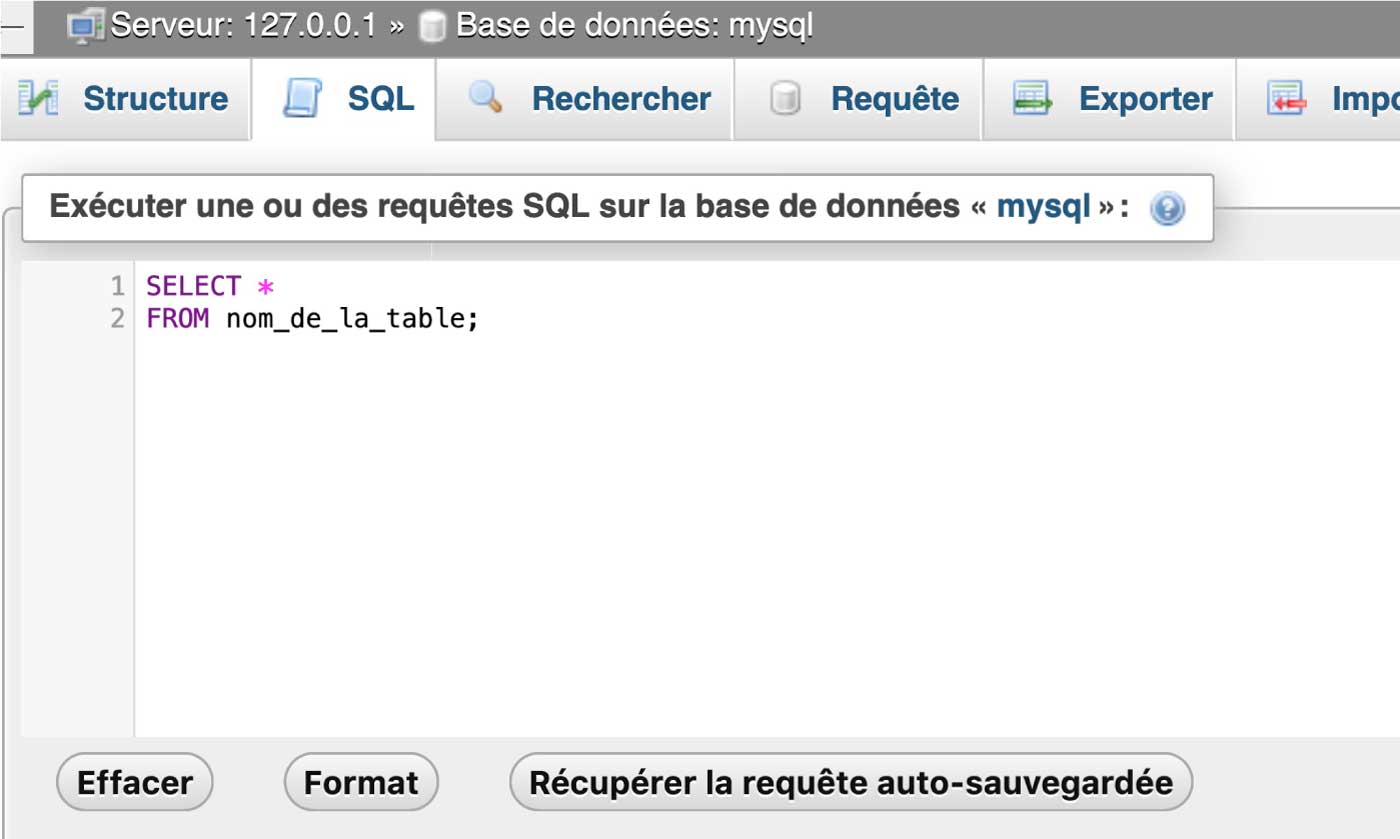
La syntaxe de base de SQL pour extraire toutes les données d’une table est la suivante :
SELECT *
FROM nom_de_la_table;
Dans cette requête, « SELECT » indique les colonnes que vous souhaitez inclure dans les résultats, et l’astérisque (*) signifie « toutes les colonnes ». « FROM » spécifie la table à partir de laquelle vous souhaitez extraire les données. La requête retournera toutes les lignes de la table spécifiée.
La syntaxe de base de SQL peut être étendue en utilisant des opérateurs, des fonctions et des clauses supplémentaires pour filtrer, trier et regrouper les données de manière plus avancée.
Les principales commandes SQL (SELECT, FROM, WHERE, GROUP BY, ORDER BY)
Les principales commandes SQL sont les suivantes :
- SELECT : permet de spécifier les colonnes que vous souhaitez inclure dans votre requête. Exemple :
SELECT colonne1, colonne2 FROM nom_de_la_table; - FROM : permet de spécifier la table à partir de laquelle vous souhaitez extraire les données. Exemple :
SELECT * FROM nom_de_la_table; - WHERE : permet de filtrer les résultats de la requête en spécifiant des conditions. Exemple :
SELECT * FROM nom_de_la_table WHERE colonne1 = 'valeur'; - GROUP BY : permet de regrouper les résultats en fonction d’une colonne spécifique. Exemple :
SELECT colonne1, COUNT(*) FROM nom_de_la_table GROUP BY colonne1; - ORDER BY : permet de trier les résultats en fonction d’une ou plusieurs colonnes. Exemple :
SELECT * FROM nom_de_la_table ORDER BY colonne1 ASC, colonne2 DESC;
En utilisant ces commandes, vous pouvez effectuer des requêtes SQL pour extraire des données spécifiques d’une table. La commande SELECT est utilisée pour spécifier les colonnes que vous souhaitez inclure dans votre requête. La commande FROM est utilisée pour spécifier la table à partir de laquelle vous souhaitez extraire les données. La commande WHERE est utilisée pour filtrer les résultats de la requête en spécifiant des conditions. La commande GROUP BY est utilisée pour regrouper les résultats en fonction d’une colonne spécifique. Enfin, la commande ORDER BY est utilisée pour trier les résultats en fonction d’une ou plusieurs colonnes.
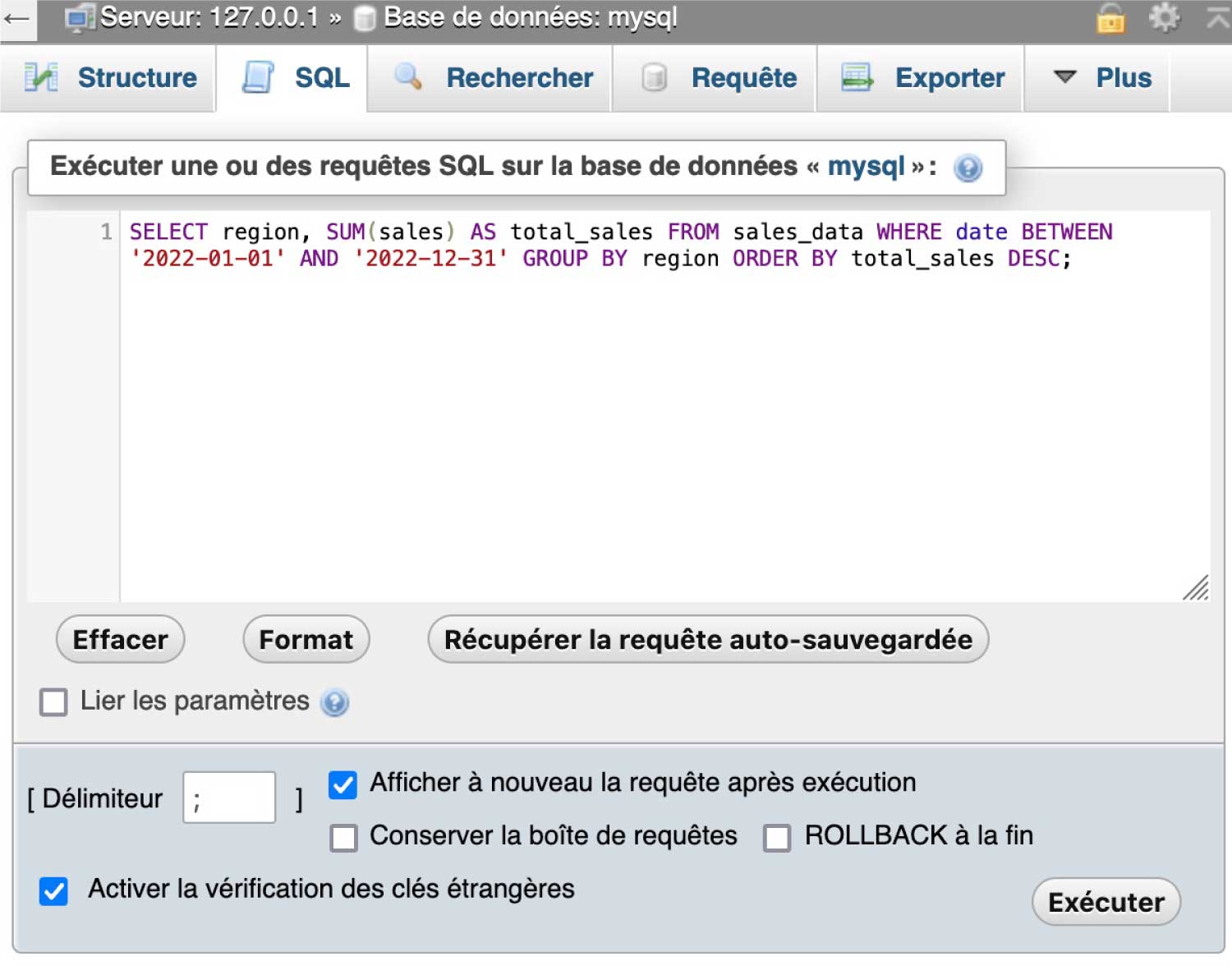
Voici un exemple de requête SQL utilisant les commandes SELECT, FROM, WHERE, GROUP BY et ORDER BY :
SELECT region, SUM(sales) AS total_sales FROM sales_data WHERE date BETWEEN '2022-01-01' AND '2022-12-31' GROUP BY region ORDER BY total_sales DESC;
Cette requête sélectionne la région et le total des ventes pour l’année 2022 à partir de la table des données de vente (sales_data), en filtrant les résultats pour les ventes effectuées entre le 1er janvier 2022 et le 31 décembre 2022. Les résultats sont ensuite regroupés par région et triés par ordre décroissant de total des ventes.
Les fonctions SQL
Les fonctions SQL sont des outils puissants pour extraire des informations spécifiques à partir de données stockées dans des tables. Dans ce chapitre, nous allons explorer les fonctions SQL les plus courantes et comment les utiliser pour manipuler et extraire des données.
Nous allons commencer par examiner les fonctions d’agrégation telles que SUM, COUNT, AVG, MAX et MIN, qui permettent d’effectuer des calculs sur un ensemble de valeurs dans une colonne spécifique d’une table. Ensuite, nous aborderons les fonctions de manipulation de chaînes de caractères telles que LEFT, RIGHT et SUBSTRING, qui permettent de manipuler des données textuelles dans une colonne spécifique.
Enfin, nous examinerons les fonctions de date et d’heure telles que DATE, YEAR, MONTH, DAY, HOUR, MINUTE et SECOND, qui permettent de manipuler des données temporelles dans une colonne spécifique. En utilisant ces fonctions, vous pourrez extraire des informations importantes à partir de grandes quantités de données stockées dans des tables SQL.
Les fonctions d’agrégation (SUM, COUNT, AVG, MAX, MIN)
Les fonctions d’agrégation sont des fonctions SQL qui permettent d’effectuer des calculs sur un ensemble de valeurs dans une colonne spécifique d’une table. Les fonctions d’agrégation les plus courantes sont les suivantes :
- SUM : calcule la somme des valeurs d’une colonne spécifique. Exemple :
SELECT SUM(colonne1) FROM nom_de_la_table; - COUNT : compte le nombre de lignes dans une table ou le nombre de valeurs dans une colonne spécifique.
Exemple :SELECT COUNT(*) FROM nom_de_la_table;
Exemple :SELECT COUNT(colonne1) FROM nom_de_la_table; - AVG : calcule la moyenne des valeurs d’une colonne spécifique. Exemple : S
ELECT AVG(colonne1) FROM nom_de_la_table; - MAX : renvoie la valeur maximale d’une colonne spécifique. Exemple :
SELECT MAX(colonne1) FROM nom_de_la_table; - MIN : renvoie la valeur minimale d’une colonne spécifique. Exemple :
SELECT MIN(colonne1) FROM nom_de_la_table;
Les fonctions d’agrégation sont souvent utilisées en conjonction avec la commande GROUP BY pour effectuer des calculs sur des sous-ensembles de données dans une table. Par exemple, pour calculer la somme des ventes pour chaque région, vous pouvez utiliser la commande GROUP BY pour regrouper les ventes par région, puis la fonction SUM pour calculer la somme des ventes pour chaque région.
Les fonctions d’agrégation sont un outil puissant pour effectuer des calculs sur les données dans une table et peuvent être utilisées pour extraire des informations importantes à partir de grandes quantités de données.
Les fonctions de manipulation de chaînes de caractères (LEFT, RIGHT, SUBSTRING)
Les fonctions de manipulation de chaînes de caractères sont utilisées pour manipuler des données textuelles stockées dans une colonne spécifique d’une table. Les fonctions les plus courantes sont les suivantes :
- LEFT : renvoie les premiers caractères d’une chaîne de caractères spécifique.
Exemple :SELECT LEFT(colonne1, 3) FROM nom_de_la_table; - RIGHT : renvoie les derniers caractères d’une chaîne de caractères spécifique.
Exemple :SELECT RIGHT(colonne1, 3) FROM nom_de_la_table; - SUBSTRING : renvoie une partie spécifique d’une chaîne de caractères en utilisant une position de départ et une longueur spécifiques.
Exemple : SELECT SUBSTRING(colonne1, 2, 5) FROM nom_de_la_table; - CONCAT : permet de concaténer plusieurs chaînes de caractères en une seule.
Exemple :SELECT CONCAT(colonne1, ' - ', colonne2) FROM nom_de_la_table; - TRIM : permet de supprimer les espaces en début et en fin de chaîne de caractères.
Exemple :SELECT TRIM(colonne1) FROM nom_de_la_table;
Ces fonctions sont souvent utilisées pour nettoyer et normaliser les données textuelles dans une colonne spécifique, en supprimant les espaces en début et en fin de chaîne, en extrayant une partie spécifique de la chaîne ou en concaténant plusieurs chaînes en une seule.
En utilisant ces fonctions, vous pouvez manipuler et extraire des données textuelles de manière efficace et précise, ce qui peut être utile dans de nombreuses situations différentes, comme dans le traitement de données de texte libre, par exemple.
Les fonctions de date et d’heure (DATE, YEAR, MONTH, DAY, HOUR, MINUTE, SECOND)
Les fonctions de date et d’heure sont utilisées pour manipuler des données temporelles stockées dans une colonne spécifique d’une table. Les fonctions les plus courantes sont les suivantes :
- DATE : convertit une chaîne de caractères en une date.
Exemple :SELECT DATE('2022-03-26') FROM nom_de_la_table; - YEAR : renvoie l’année d’une date spécifique.
Exemple :SELECT YEAR(date_colonne) FROM nom_de_la_table; - MONTH : renvoie le mois d’une date spécifique.
Exemple :SELECT MONTH(date_colonne) FROM nom_de_la_table; - DAY : renvoie le jour d’une date spécifique.
Exemple :SELECT DAY(date_colonne) FROM nom_de_la_table; - HOUR : renvoie l’heure d’une date spécifique.
Exemple :SELECT HOUR(date_colonne) FROM nom_de_la_table; - MINUTE : renvoie les minutes d’une date spécifique.
Exemple :SELECT MINUTE(date_colonne) FROM nom_de_la_table; - SECOND : renvoie les secondes d’une date spécifique.
Exemple :SELECT SECOND(date_colonne) FROM nom_de_la_table;
Ces fonctions sont souvent utilisées pour extraire des informations spécifiques à partir de données temporelles dans une colonne spécifique, en extrayant l’année, le mois, le jour, l’heure, les minutes ou les secondes. Ces informations peuvent être utiles dans de nombreuses situations différentes, par exemple pour calculer des écarts de temps entre deux événements, pour analyser des tendances sur une période de temps donnée ou pour filtrer les données en fonction d’une période de temps spécifique.
La gestion des données avec SQL
La gestion des données est l’un des aspects les plus importants de l’analyse de données. Dans ce chapitre, nous allons explorer comment gérer les données avec SQL.
Nous commencerons par examiner la commande INSERT, qui permet d’insérer de nouvelles lignes dans une table. Ensuite, nous aborderons la commande UPDATE, qui permet de mettre à jour les données existantes dans une table. Nous examinerons également la commande DELETE, qui permet de supprimer des lignes dans une table.
Enfin, nous aborderons les concepts de jointure et de sous-requête, qui permettent de combiner les données de plusieurs tables pour obtenir des informations plus complexes. En utilisant ces commandes et ces concepts, vous pourrez gérer les données dans une base de données relationnelle de manière efficace et précise.
La création et la suppression de tables
La création et la suppression de tables sont des opérations de base dans SQL. Les tables sont utilisées pour stocker et organiser les données dans une base de données relationnelle. Dans cette section, nous allons examiner comment créer et supprimer des tables en SQL.
Pour créer une table en SQL, vous devez spécifier le nom de la table et les colonnes que vous souhaitez inclure dans la table. Les colonnes sont définies par leur nom et leur type de données. La commande CREATE TABLE est utilisée pour créer une nouvelle table. Voici un exemple de syntaxe :
CREATE TABLE nom_de_la_table (
colonne1 type_de_donnees1,
colonne2 type_de_donnees2,
colonne3 type_de_donnees3
);
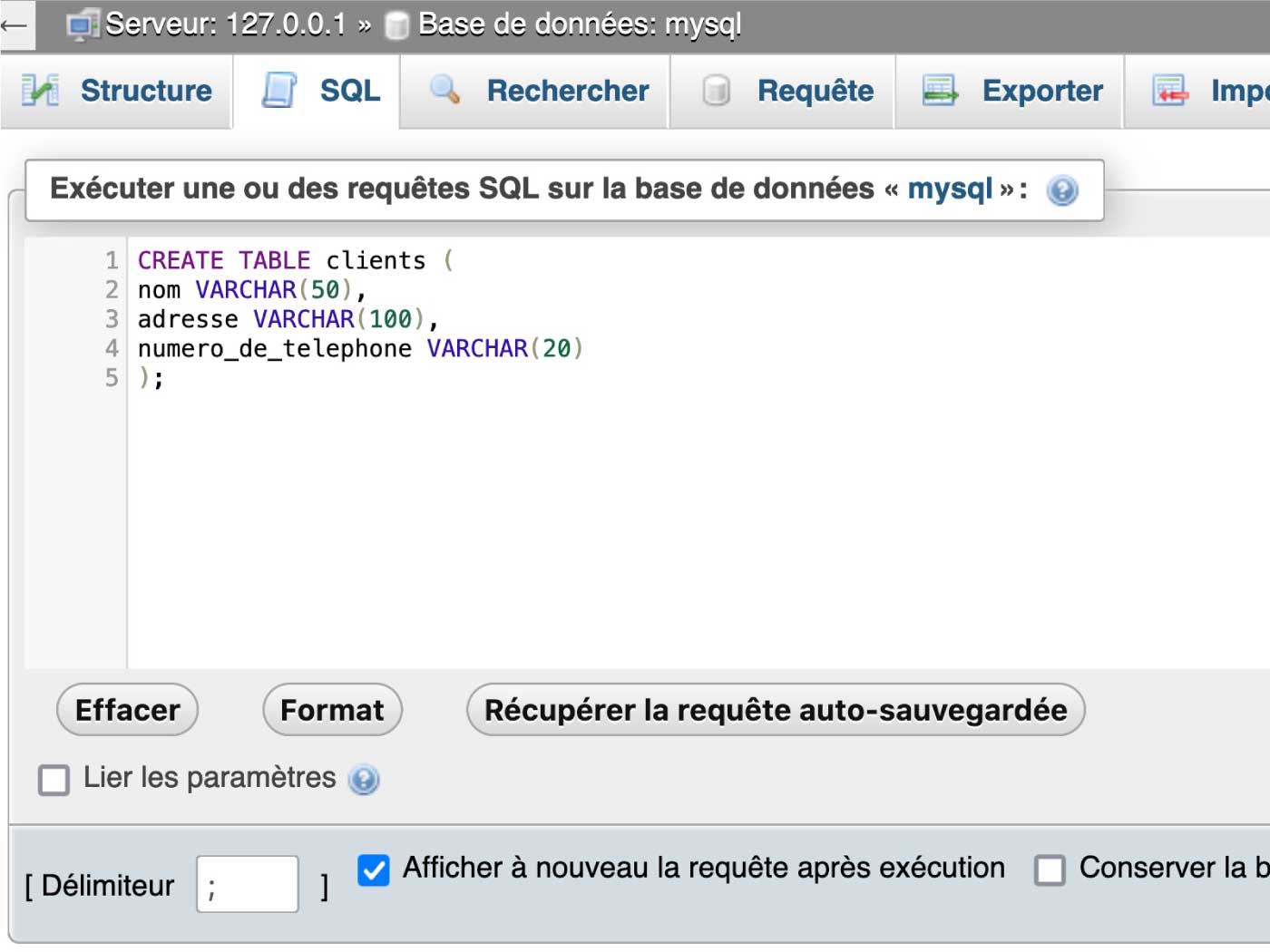
Donc par exemple, pour créer une table de clients avec des colonnes pour le nom, l’adresse et le numéro de téléphone, vous pouvez utiliser la commande suivante :
CREATE TABLE clients (
nom VARCHAR(50),
adresse VARCHAR(100),
numero_de_telephone VARCHAR(20)
);
Pour supprimer une table en SQL, vous pouvez utiliser la commande DROP TABLE. Voici un exemple de syntaxe :
DROP TABLE nom_de_la_table;
Par exemple, pour supprimer la table clients, vous pouvez utiliser la commande suivante :
DROP TABLE clients;
Il est important de noter que la suppression d’une table est une opération définitive et que toutes les données qu’elle contient seront perdues. Avant de supprimer une table, assurez-vous de sauvegarder toutes les données importantes qu’elle contient.
La modification des données dans une table (INSERT, UPDATE, DELETE)
La modification des données dans une table est un aspect essentiel de la gestion des données en SQL. Il existe trois commandes de base pour modifier les données dans une table : INSERT, UPDATE et DELETE.
- INSERT : la commande INSERT permet d’insérer de nouvelles lignes dans une table. La syntaxe de base est la suivante :
INSERT INTO nom_de_la_table (colonne1, colonne2, colonne3)Par exemple, pour insérer une nouvelle ligne dans la table clients avec des valeurs pour les colonnes nom, adresse et numéro de téléphone, vous pouvez utiliser la commande suivante :
VALUES (valeur1, valeur2, valeur3);INSERT INTO clients (nom, adresse, numero_de_telephone)
VALUES ('Jean Dupont', '123 rue de la Paix', '0123456789'); - UPDATE : la commande UPDATE permet de mettre à jour les données existantes dans une table. La syntaxe de base est la suivante :
UPDATE nom_de_la_tablePar exemple, pour mettre à jour le numéro de téléphone pour le client avec l’ID 1, vous pouvez utiliser la commande suivante :
SET colonne = nouvelle_valeur
WHERE condition;
UPDATE clients
SET numero_de_telephone = '9876543210'
WHERE id = 1; - DELETE : la commande DELETE permet de supprimer des lignes dans une table. La syntaxe de base est la suivante :
DELETE FROM nom_de_la_tablePar exemple, pour supprimer le client avec l’ID 1, vous pouvez utiliser la commande suivante :
WHERE condition;DELETE FROM clientsIl est important de noter que la commande DELETE est une opération définitive et que toutes les données correspondantes seront supprimées de manière permanente. Avant d’exécuter une commande DELETE, assurez-vous de sauvegarder toutes les données importantes qu’elle contient.
WHERE id = 1;
La jointure de tables
La jointure de tables est une opération fondamentale en SQL qui permet de combiner les données de deux ou plusieurs tables en fonction d’une clé commune. Les jointures sont utilisées pour extraire des informations plus complexes à partir de bases de données relationnelles.
Il existe plusieurs types de jointures en SQL, les plus courantes étant :
- INNER JOIN : cette jointure renvoie uniquement les lignes qui ont des correspondances dans les deux tables.
SELECT *
FROM table1
INNER JOIN table2
ON table1.colonne = table2.colonne; - LEFT JOIN : cette jointure renvoie toutes les lignes de la table de gauche (table1) et les correspondances de la table de droite (table2). Si aucune correspondance n’est trouvée, les valeurs de la table de droite seront NULL.
SELECT *
FROM table1
LEFT JOIN table2
ON table1.colonne = table2.colonne; - RIGHT JOIN : cette jointure est similaire à LEFT JOIN, mais renvoie toutes les lignes de la table de droite (table2) et les correspondances de la table de gauche (table1). Si aucune correspondance n’est trouvée, les valeurs de la table de gauche seront NULL.
SELECT *
FROM table1
RIGHT JOIN table2
ON table1.colonne = table2.colonne; - FULL OUTER JOIN : cette jointure renvoie toutes les lignes des deux tables et combine les lignes correspondantes en une seule ligne. Si aucune correspondance n’est trouvée, les valeurs seront NULL.
SELECT *
FROM table1
FULL OUTER JOIN table2
ON table1.colonne = table2.colonne;
Il est important de noter que les jointures peuvent être utilisées pour combiner des tables avec des millions de lignes, mais elles peuvent également être utilisées pour combiner des tables plus petites avec des dizaines ou des centaines de lignes. Les jointures sont un outil puissant pour extraire des informations complexes à partir de bases de données relationnelles.
L’optimisation des requêtes SQL
L’optimisation des requêtes SQL est un aspect important de l’analyse de données, car elle peut avoir un impact significatif sur les performances et la rapidité d’exécution des requêtes. Dans cette section, nous allons examiner l’importance de l’optimisation des requêtes SQL et les techniques que vous pouvez utiliser pour optimiser les requêtes.
L’importance de l’optimisation des requêtes SQL
Les requêtes SQL peuvent devenir très complexes et consommer beaucoup de ressources système lorsqu’elles sont exécutées sur des bases de données volumineuses. Cela peut entraîner des temps d’exécution plus longs et ralentir les performances globales du système. L’optimisation des requêtes SQL peut aider à réduire ces temps d’exécution et à améliorer les performances du système.
Les techniques d’optimisation des requêtes SQL
- Utilisation d’index : les index sont utilisés pour accélérer la recherche de données dans une table. En créant un index sur une colonne spécifique, vous pouvez accélérer les requêtes qui recherchent des données dans cette colonne. Il est important de noter que la création d’index peut ralentir les performances des opérations d’insertion et de mise à jour de données.
- Optimisation des requêtes : en utilisant les commandes SQL de manière optimale, vous pouvez réduire le temps d’exécution des requêtes. Cela peut inclure l’utilisation de jointures efficaces, l’optimisation des clauses WHERE et l’utilisation appropriée des fonctions d’agrégation.
- Utilisation de vues : les vues sont des tables virtuelles qui sont créées à partir d’une ou plusieurs tables existantes. Les vues peuvent être utilisées pour simplifier les requêtes complexes et réduire les temps d’exécution. Les vues peuvent également être utilisées pour restreindre l’accès à certaines données dans une table.
En utilisant ces techniques, vous pouvez optimiser les requêtes SQL pour améliorer les performances et réduire les temps d’exécution. Cependant, il est important de noter que l’optimisation des requêtes peut être un processus complexe et qu’il peut être nécessaire de faire des compromis entre la vitesse d’exécution et l’exactitude des résultats.
Les outils d’analyse de données SQL
Les outils d’analyse de données SQL sont des applications logicielles qui permettent aux utilisateurs d’extraire des données à partir de bases de données relationnelles à l’aide de SQL et de les analyser. Ces outils sont utilisés pour explorer les données en profondeur, détecter les tendances et les modèles et prendre des décisions commerciales éclairées.
Dans ce chapitre, nous allons examiner les différents types d’outils d’analyse de données SQL disponibles sur le marché et les fonctionnalités clés qu’ils offrent. Nous allons également discuter de l’importance de la sélection d’un outil d’analyse de données SQL approprié en fonction de vos besoins spécifiques en matière d’analyse de données. En fin de compte, l’utilisation d’un outil d’analyse de données SQL efficace peut aider les entreprises à prendre des décisions plus éclairées et à améliorer leurs performances commerciales.
Les outils de visualisation de données
Les outils de visualisation de données sont des applications logicielles utilisées pour créer des graphiques, des tableaux de bord et des rapports visuels à partir de données. Ces outils sont utilisés pour explorer et communiquer des informations clés à partir de grandes quantités de données.
Deux des outils de visualisation de données les plus populaires sont Tableau et Power BI.
- Tableau : Tableau est un outil de visualisation de données utilisé pour créer des graphiques interactifs, des tableaux de bord et des rapports visuels à partir de données. Tableau permet aux utilisateurs de se connecter à une variété de sources de données, notamment des fichiers Excel, des bases de données relationnelles et des sources de données cloud. Les utilisateurs peuvent ensuite utiliser l’interface glisser-déposer de Tableau pour créer des visualisations et des tableaux de bord personnalisés. Tableau offre également des fonctionnalités de collaboration et de partage pour permettre aux utilisateurs de travailler ensemble sur des projets de visualisation de données.
- Power BI : Power BI est un outil de visualisation de données de Microsoft utilisé pour créer des tableaux de bord et des rapports visuels à partir de données. Power BI permet aux utilisateurs de se connecter à une variété de sources de données, notamment des fichiers Excel, des bases de données relationnelles et des sources de données cloud. Les utilisateurs peuvent ensuite utiliser les fonctionnalités de glisser-déposer de Power BI pour créer des visualisations et des tableaux de bord interactifs. Power BI offre également des fonctionnalités de collaboration et de partage pour permettre aux utilisateurs de travailler ensemble sur des projets de visualisation de données.
Ces outils de visualisation de données sont très populaires car ils offrent des moyens simples et intuitifs pour visualiser et comprendre les données. Ils permettent également aux utilisateurs de collaborer facilement sur des projets de visualisation de données et de partager les résultats avec d’autres personnes. En utilisant ces outils, les analystes de données peuvent explorer les données en profondeur et communiquer les résultats de manière claire et concise.
Les outils de traitement de données
Les outils de traitement de données sont des applications logicielles utilisées pour analyser et traiter des données. Il existe plusieurs outils de traitement de données populaires, notamment Python, R, SAS, SPSS et MATLAB.
- Python : Python est un langage de programmation open source utilisé pour l’analyse de données, l’apprentissage automatique et le traitement du langage naturel. Python offre de nombreuses bibliothèques et modules pour le traitement de données, tels que Pandas, NumPy et Matplotlib.
- R : R est un langage de programmation open source utilisé pour l’analyse de données, la statistique et la visualisation. R offre également de nombreuses bibliothèques pour le traitement de données, telles que dplyr, tidyr et ggplot2.
- SAS : SAS est un logiciel commercial utilisé pour l’analyse de données, la statistique et la visualisation. SAS offre des fonctionnalités pour le traitement de données, telles que SAS Data Integration Studio et SAS DataFlux.
- SPSS : SPSS est un logiciel commercial utilisé pour l’analyse de données, la statistique et la visualisation. SPSS offre des fonctionnalités pour le traitement de données, telles que le nettoyage de données, la transformation de données et l’analyse des données manquantes.
- MATLAB : MATLAB est un langage de programmation et un environnement de développement utilisé pour l’analyse de données, l’apprentissage automatique et la modélisation mathématique. MATLAB offre de nombreuses bibliothèques pour le traitement de données, telles que MATLAB Data Analytics Toolbox et MATLAB Statistics and Machine Learning Toolbox.
Ces outils de traitement de données sont très populaires car ils offrent une grande flexibilité et une large gamme de fonctionnalités pour le traitement de données. En utilisant ces outils, les analystes de données peuvent nettoyer, transformer et analyser les données de manière efficace et précise. Cependant, le choix de l’outil de traitement de données approprié dépend des besoins spécifiques de chaque projet d’analyse de données.
Les outils de gestion de base de données
Les outils de gestion de base de données sont des applications logicielles utilisées pour administrer et gérer des bases de données. Ces outils sont utilisés pour créer, modifier, maintenir et gérer des bases de données, des tables et des vues, ainsi que pour effectuer des tâches d’administration de base de données telles que la sauvegarde et la restauration de données.
Il existe plusieurs outils de gestion de base de données populaires, tels que MySQL Workbench, Microsoft SQL Server Management Studio, Oracle SQL Developer, PostgreSQL et SQLite.
- MySQL Workbench : MySQL Workbench est un outil de gestion de base de données open source utilisé pour la création, la conception et la gestion de bases de données MySQL. MySQL Workbench offre des fonctionnalités pour la création de diagrammes de base de données, la modélisation de données, la gestion de serveurs et la migration de données.
- Microsoft SQL Server Management Studio : Microsoft SQL Server Management Studio est un outil de gestion de base de données utilisé pour la gestion de bases de données SQL Server de Microsoft. Il offre des fonctionnalités pour la création de diagrammes de base de données, la gestion de serveurs, la création de requêtes SQL et la gestion de la sécurité des bases de données.
- Oracle SQL Developer : Oracle SQL Developer est un outil de gestion de base de données utilisé pour la création, la conception et la gestion de bases de données Oracle. Il offre des fonctionnalités pour la création de diagrammes de base de données, la gestion de serveurs, la création de requêtes SQL et la gestion de la sécurité des bases de données.
- PostgreSQL : PostgreSQL est un système de gestion de base de données open source. Il offre des fonctionnalités pour la création, la conception et la gestion de bases de données PostgreSQL. PostgreSQL peut être géré à l’aide de plusieurs outils, tels que pgAdmin, DataGrip et Navicat.
- SQLite : SQLite est un système de gestion de base de données open source. Il est léger, facile à utiliser et largement utilisé dans les applications mobiles et Web. SQLite peut être géré à l’aide de plusieurs outils, tels que SQLiteStudio, DB Browser for SQLite et Valentina Studio.
Ces outils de gestion de base de données sont essentiels pour les administrateurs de bases de données et les développeurs d’applications qui travaillent avec des bases de données relationnelles. En utilisant ces outils, les administrateurs de bases de données peuvent gérer efficacement les bases de données, tandis que les développeurs peuvent créer et exécuter des requêtes SQL pour extraire des données de manière efficace et précise.
Les bonnes pratiques SQL
La normalisation des bases de données
La normalisation des bases de données est un processus qui consiste à organiser les données dans une base de données relationnelle pour éviter la duplication de données et garantir l’intégrité des données. La normalisation permet de réduire les erreurs de données et d’améliorer l’efficacité des requêtes SQL.
La normalisation des bases de données implique la création de plusieurs tables, chacune contenant des informations spécifiques sur un seul sujet ou une seule entité. Les tables sont ensuite liées entre elles à l’aide de clés primaires et étrangères pour permettre aux utilisateurs de récupérer des informations à partir de plusieurs tables en utilisant des requêtes SQL.
Il existe plusieurs niveaux de normalisation des bases de données, appelés formes normales, allant de la première forme normale (1NF) à la cinquième forme normale (5NF). Chaque forme normale a des règles spécifiques pour garantir que les données sont correctement structurées et normalisées.
Voici les règles clés pour chaque forme normale :
- Première forme normale (1NF) : Les données doivent être atomiques, c’est-à-dire qu’elles ne doivent pas être divisibles en parties plus petites.
- Deuxième forme normale (2NF) : Toutes les colonnes d’une table doivent dépendre de la clé primaire de cette table.
- Troisième forme normale (3NF) : Toutes les colonnes d’une table doivent être fonctionnellement dépendantes de la clé primaire de cette table, et non d’autres colonnes de la même table.
- Quatrième forme normale (4NF) : Les colonnes non clés doivent être dépendantes de la clé primaire de la table, et non de manière transitive d’autres colonnes non clés.
- Cinquième forme normale (5NF) : Les informations sont stockées de manière à éviter les anomalies de mise à jour.
La normalisation des bases de données est importante car elle permet de garantir l’intégrité des données, de réduire la duplication de données et de faciliter la maintenance de la base de données. Cependant, il est important de noter que la normalisation excessive peut entraîner des performances de requête plus lentes. Il est donc important de trouver le bon équilibre entre la normalisation et la performance.
La sécurisation des données
La sécurisation des données est un élément crucial de toute base de données, car elle garantit la protection des informations sensibles contre les accès non autorisés, les attaques malveillantes et les pertes de données. Voici quelques pratiques clés pour sécuriser les données :
- Utilisation de mots de passe forts : Les mots de passe doivent être suffisamment complexes et difficiles à deviner pour éviter les accès non autorisés. Les utilisateurs doivent également être encouragés à changer régulièrement leurs mots de passe.
- Gestion des autorisations d’accès : Les autorisations d’accès doivent être attribuées en fonction des rôles et des responsabilités de chaque utilisateur. Les utilisateurs ne doivent avoir accès qu’aux données nécessaires à l’exécution de leurs tâches.
- Cryptage des données : Les données sensibles doivent être cryptées pour empêcher les accès non autorisés. Les données doivent également être cryptées lorsqu’elles sont en transit pour éviter qu’elles ne soient interceptées.
- Sauvegarde régulière des données : Les données doivent être sauvegardées régulièrement pour éviter les pertes de données en cas de défaillance du système ou d’attaque malveillante.
- Utilisation de logiciels antivirus et de pare-feu : Les logiciels antivirus et les pare-feu doivent être utilisés pour détecter et empêcher les attaques malveillantes.
- Mises à jour régulières des logiciels : Les mises à jour des logiciels doivent être effectuées régulièrement pour corriger les vulnérabilités et les failles de sécurité.
- Formation des utilisateurs : Les utilisateurs doivent être formés sur les meilleures pratiques de sécurité des données et les risques potentiels pour éviter les erreurs humaines qui peuvent causer des vulnérabilités.
La sécurisation des données est un processus continu et doit être maintenue régulièrement pour garantir la protection des données. Les entreprises doivent également se conformer aux réglementations de sécurité des données telles que le RGPD en Europe et le CCPA en Californie pour garantir la protection des données personnelles de leurs clients.
L’optimisation des performances
Les performances de la base de données peuvent avoir un impact significatif sur l’efficacité de l’analyse de données. Pour optimiser les performances, il est important de bien concevoir la base de données et d’utiliser des requêtes SQL optimisées. Il est également important de surveiller les performances de la base de données et d’identifier et de résoudre les problèmes de performances le plus rapidement possible. Certaines techniques d’optimisation des performances incluent l’indexation, la normalisation, la dénormalisation, l’utilisation de vues et la mise en cache.
La documentation des requêtes SQL
La documentation des requêtes SQL est importante pour faciliter la compréhension et la maintenance des requêtes SQL. La documentation peut inclure des commentaires détaillant le but et la logique de la requête, ainsi que des informations sur les sources de données utilisées. La documentation des requêtes SQL peut également aider à résoudre les problèmes de performances et à améliorer la qualité de l’analyse de données.
L’optimisation des performances et la documentation des requêtes SQL sont des aspects clés de l’analyse de données. En utilisant des techniques d’optimisation des performances et en documentant correctement les requêtes SQL, les entreprises peuvent améliorer l’efficacité de l’analyse de données, résoudre les problèmes de performances et améliorer la qualité de l’analyse de données.
Conclusion
En conclusion, SQL est un langage de programmation essentiel pour l’analyse de données. Il permet aux entreprises de stocker, de gérer, de manipuler et d’extraire des données de manière efficace et précise. L’optimisation des requêtes SQL, la normalisation des bases de données, la sécurité des données, l’optimisation des performances et la documentation des requêtes SQL sont toutes des pratiques importantes pour maximiser l’efficacité de l’analyse de données.
L’avenir de SQL et de l’analyse de données est prometteur, avec une utilisation croissante de l’analyse de données dans de nombreux domaines, tels que la finance, la santé, le marketing et l’ingénierie. Les entreprises continueront à chercher des moyens d’exploiter les données pour prendre des décisions plus informées et plus stratégiques, ce qui renforce encore davantage l’importance de SQL et de l’analyse de données dans l’environnement commercial actuel.
En fin de compte, la compréhension de SQL et la capacité à travailler avec des bases de données sont des compétences essentielles pour les analystes de données, les ingénieurs de données et les développeurs de logiciels qui souhaitent réussir dans le domaine de l’analyse de données.
Foire aux question sur SQL
Qu’est-ce que SQL et à quoi sert-il ?
SQL (Structured Query Language) est un langage de programmation utilisé pour stocker, gérer, manipuler et extraire des données de bases de données relationnelles. Il permet aux entreprises de stocker et de gérer de grandes quantités de données, ainsi que d’extraire des informations utiles à partir de ces données.
Pourquoi SQL est-il important dans l’analyse de données ?
SQL est important dans l’analyse de données car il permet aux analystes de données de stocker et de gérer de grandes quantités de données, ainsi que de les extraire pour effectuer des analyses approfondies. Les requêtes SQL peuvent être utilisées pour extraire des informations précises à partir de bases de données relationnelles, ce qui permet aux entreprises de prendre des décisions plus éclairées et plus stratégiques.
Quelles sont les compétences nécessaires pour travailler avec SQL ?
Les compétences nécessaires pour travailler avec SQL comprennent la compréhension des bases de données relationnelles, la connaissance des commandes SQL de base, la capacité à écrire des requêtes SQL complexes et la compréhension des techniques d’optimisation des requêtes SQL.
Quels sont les outils les plus couramment utilisés avec SQL ?
Les outils les plus couramment utilisés avec SQL incluent les outils de gestion de base de données tels que MySQL Workbench, Microsoft SQL Server Management Studio et Oracle SQL Developer, ainsi que les outils d’analyse de données tels que Tableau et Power BI.
Quelles sont les techniques d’optimisation des requêtes SQL ?
Les techniques d’optimisation des requêtes SQL incluent l’utilisation d’index, l’optimisation des requêtes, l’utilisation de vues et la dénormalisation des tables.
Comment sécuriser les données stockées dans une base de données SQL ?
Pour sécuriser les données stockées dans une base de données SQL, il est recommandé d’utiliser des mots de passe forts, de gérer les autorisations d’accès, de crypter les données, de sauvegarder régulièrement les données, d’utiliser des logiciels antivirus et des pare-feu, de mettre à jour régulièrement les logiciels et de former les utilisateurs à la sécurité des données.