Apache Kafka
Points abordés dans cet article
Mis à jour le 22 juin 2025
🔥 Apache Kafka en quelques mots
- Qu’est-ce que c’est ? Plateforme de streaming distribuée, conçue pour le traitement de données en temps réel à grande échelle.
- Fonctionnement : Architecture publication-abonnement (pub/sub), avec producers, consumers, brokers et topics partitionnés et répliqués.
- Composants clés : Topics, partitions, producteurs, consommateurs, brokers Kafka, coordination via ZooKeeper.
- Pré-requis : Serveurs/VMs, installation de Kafka, plan de déploiement, architecture de traitement, producteurs et consommateurs.
- Cas d’usage :
- 📊 Analyse de données en temps réel
- 🔧 Surveillance d’équipements (IoT, industrie)
- 💳 Traitement de transactions & détection de fraudes
- 🪵 Centralisation des logs système & application
- Confluent Platform : Version enrichie de Kafka avec outils complémentaires (gestion de schémas, monitoring, connecteurs, cloud).
- Avantages : Haute performance, faible latence, scalabilité horizontale, tolérance aux pannes, écosystème riche.
🎯 En résumé : Kafka est une solution puissante et robuste pour les entreprises souhaitant traiter, acheminer et exploiter des flux de données massifs en temps réel.
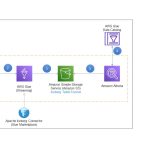
Apache Kafka est une plateforme de streaming distribuée qui a été développée à l’origine par LinkedIn et plus tard rendue open-source via la fondation Apache Software. Elle est conçue pour gérer le traitement de données à grande échelle en temps réel, ce qui la rend particulièrement utile pour les applications qui nécessitent un streaming de données à haut débit et à faible latence.
Le système de publication-abonnement (pub-sub) est l’une des fonctionnalités clés de Kafka, qui permet aux producteurs de données de publier des messages sur des sujets spécifiques et aux consommateurs de données de s’abonner à ces sujets pour recevoir les messages. Les messages sont stockés dans des topics et distribués aux consommateurs de manière fiable et efficace, garantissant ainsi que les données sont disponibles et accessibles en temps réel.
Compréhension de base des fonctionnalités et des concepts clés d’Apache Kafka
Pour avoir une compréhension de base des fonctionnalités et des concepts clés d’Apache Kafka, voici quelques éléments à connaître :
Système de publication-abonnement (pub-sub)
Apache Kafka utilise une architecture pub-sub pour la distribution de messages en temps réel. Les producteurs de données envoient des messages à un broker Kafka, qui stocke et distribue les messages aux consommateurs. Les messages sont stockés dans des topics, qui sont des flux de données partitionnés et répliqués sur plusieurs brokers Kafka pour garantir la disponibilité des données.
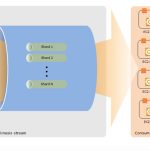
Topics et partitions
Les topics sont les flux de données dans Kafka, et les partitions sont les unités de stockage pour les données dans les topics. Les partitions permettent de distribuer les données de manière efficace et de les traiter en parallèle. Les messages sont stockés dans les partitions, et chaque partition est répliquée sur plusieurs brokers Kafka pour garantir la disponibilité des données.
Producteurs et consommateurs
Les producteurs de données envoient des messages à Kafka, tandis que les consommateurs récupèrent les messages à partir de Kafka. Les producteurs et les consommateurs peuvent être des applications ou des services qui communiquent avec les brokers Kafka pour envoyer et récupérer des messages à partir de topics spécifiques.
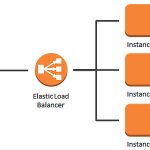
Les brokers Kafka
Les brokers Kafka sont les serveurs responsables du stockage et de la distribution des messages dans Kafka. Ils sont conçus pour être distribués, résilients et hautement disponibles, ce qui signifie qu’ils peuvent être configurés pour gérer de grandes quantités de données en temps réel de manière efficace.
ZooKeeper
ZooKeeper est un service de coordination distribué utilisé par Kafka pour la gestion des brokers, des topics, des partitions et des groupes de consommateurs. ZooKeeper maintient les informations sur l’état de la grappe Kafka et les met à jour en temps réel, permettant ainsi aux brokers Kafka de travailler ensemble pour stocker et distribuer les données de manière efficace.
Apache Kafka est un système de streaming distribué conçu pour gérer de grandes quantités de données en temps réel. Il utilise une architecture pub-sub pour la distribution de messages, des topics et des partitions pour le stockage et la distribution des données, des producteurs et des consommateurs pour envoyer et récupérer des messages, des brokers Kafka pour le stockage et la distribution des messages, et ZooKeeper pour la gestion et la coordination des brokers Kafka.
De quoi ai je besoin pour utiliser Apache Kafka pour mon entreprise?
Pour utiliser Apache Kafka pour votre entreprise, vous aurez besoin des éléments suivants :
Des serveurs ou des machines virtuelles
vous aurez besoin de plusieurs serveurs ou machines virtuelles pour exécuter les brokers Kafka, qui sont les serveurs responsables du stockage et de la distribution des messages. Il est recommandé d’avoir au moins trois brokers pour garantir la haute disponibilité et la résilience aux pannes.
Apache Kafka
vous devrez installer et configurer Apache Kafka sur chaque serveur ou machine virtuelle. Vous pouvez télécharger Apache Kafka gratuitement à partir du site web d’Apache.
Un plan de déploiement
vous devez élaborer un plan de déploiement pour votre architecture Kafka, qui décrit comment les différents composants seront déployés et configurés.
Des producteurs et des consommateurs
vous aurez besoin de producteurs et de consommateurs pour envoyer et récupérer des messages à partir de Kafka. Les producteurs sont des applications ou des services qui envoient des messages à Kafka, et les consommateurs sont des applications ou des services qui récupèrent des messages à partir de Kafka.
Des topics
vous devez créer des topics pour les différents flux de données que vous souhaitez gérer avec Kafka. Les topics sont des flux de données partitionnés et répliqués sur plusieurs brokers Kafka pour garantir la disponibilité des données.
Une architecture de traitement de données
vous devez concevoir une architecture de traitement de données qui utilise Kafka pour collecter, stocker et traiter les données en temps réel. Cela peut inclure des outils d’ETL, des moteurs de traitement de flux, des outils d’analyse de données et des outils de visualisation de données.
Pour utiliser Apache Kafka pour votre entreprise, vous aurez besoin de serveurs ou de machines virtuelles pour exécuter les brokers Kafka, d’Apache Kafka lui-même, d’un plan de déploiement, de producteurs et de consommateurs, de topics, et d’une architecture de traitement de données.
La plateforme Confluent
Confluent.io est une entreprise fondée par les créateurs d’Apache Kafka, qui propose une plateforme de streaming de données basée sur Kafka. Cette plateforme, appelée Confluent Platform, permet aux entreprises de gérer, traiter et diffuser des flux de données en temps réel de manière scalable et fiable.
La plateforme de Confluent est construite sur Apache Kafka, mais elle propose également des outils supplémentaires pour aider les entreprises à gérer et à déployer Kafka plus facilement. Ces outils incluent des fonctionnalités telles que la gestion des schémas de données, la surveillance et la gestion des flux de données, ainsi que des intégrations avec d’autres technologies de l’écosystème de données, telles que Apache Hadoop et Spark.
Confluent.io propose également une version open-source de sa plateforme appelée Confluent Community, ainsi que des solutions cloud basées sur Confluent Platform pour simplifier le déploiement de Kafka dans le cloud.
En utilisant Confluent Platform, les entreprises peuvent ingérer des données à partir de différentes sources, telles que des bases de données, des applications, des capteurs, etc., et les distribuer à des applications de traitement en temps réel, de stockage de données ou d’analyse. Cela permet aux entreprises de réagir plus rapidement aux événements en temps réel et de prendre des décisions plus éclairées.
Exemples de cas concret auxquels Apache Kafka répond pour les entreprises
Apache Kafka peut être utilisé dans de nombreux cas d’utilisation pour aider les entreprises à gérer et à traiter des flux de données en temps réel. Voici quelques exemples de cas concrets auxquels Apache Kafka répond pour les entreprises :
Analyse de données en temps réel
Apache Kafka peut être utilisé pour collecter et traiter des données en temps réel pour l’analyse et la prise de décisions en temps réel. Les entreprises peuvent collecter des données à partir de sources telles que les capteurs IoT, les réseaux sociaux, les transactions en ligne, et les analyser en temps réel pour détecter les tendances et les anomalies.
Surveillance de l’état des équipements
Les entreprises peuvent utiliser Apache Kafka pour collecter et analyser des données en temps réel à partir d’équipements tels que des machines industrielles, des véhicules et des avions. Cela permet aux entreprises de surveiller l’état des équipements en temps réel, de détecter les problèmes et les pannes, et de prendre des mesures préventives pour éviter les interruptions coûteuses.
Traitement de transactions en temps réel
Apache Kafka peut être utilisé pour collecter et traiter des transactions en temps réel, telles que les transactions financières ou les transactions de commerce électronique. Cela permet aux entreprises de surveiller les transactions en temps réel, de détecter les fraudes et les anomalies, et de prendre des mesures préventives pour éviter les pertes financières.
Gestion de logs
Les entreprises peuvent utiliser Apache Kafka pour collecter et stocker des logs système et des logs d’application en temps réel. Cela permet aux entreprises de surveiller l’état de leurs systèmes et applications, de détecter les problèmes et les pannes, et de prendre des mesures pour les résoudre avant qu’ils ne causent des perturbations.
Apache Kafka répond à de nombreux cas d’utilisation pour les entreprises, tels que l’analyse de données en temps réel, la surveillance de l’état des équipements, le traitement de transactions en temps réel, et la gestion de logs. Cela permet aux entreprises de collecter, stocker et traiter des données en temps réel de manière fiable et efficace.
La foire aux questions
Qu’est-ce qu’Apache Kafka ?
Apache Kafka est une plateforme de streaming distribuée, utilisée pour la gestion de flux de données en temps réel. Elle est utilisée pour collecter, stocker et traiter de grandes quantités de données en temps réel, en permettant aux producteurs de publier des messages sur des topics spécifiques, et aux consommateurs de s’abonner à ces topics pour récupérer les messages correspondants.
Pourquoi utiliser Apache Kafka ?
Apache Kafka est utilisé pour de nombreuses applications, telles que l’analyse de données en temps réel, la surveillance de l’état des équipements, le suivi des transactions en temps réel, la détection d’anomalies et la prévention de la fraude. Elle permet de gérer les flux de données en temps réel de manière fiable et efficace, en offrant des avantages tels que la scalabilité, la haute disponibilité et la résilience aux pannes.
Comment fonctionne Apache Kafka ?
Apache Kafka utilise une architecture pub-sub (publication-abonnement) pour la distribution de messages en temps réel. Les producteurs de données envoient des messages à un broker Kafka, qui stocke et distribue les messages aux consommateurs. Les messages sont stockés dans des topics, qui sont des flux de données partitionnés et répliqués sur plusieurs brokers Kafka pour garantir la disponibilité des données.
Comment mettre en place un système Kafka ?
Pour mettre en place un système Kafka, vous devez d’abord installer et configurer les brokers Kafka, qui sont les serveurs responsables du stockage et de la distribution des messages. Ensuite, vous devez créer des topics pour les différents flux de données que vous souhaitez gérer, et configurer les producteurs et les consommateurs pour envoyer et récupérer des messages à partir de ces topics.
Quels sont les avantages de Kafka par rapport à d’autres plateformes de streaming de données ?
Kafka offre plusieurs avantages par rapport à d’autres plateformes de streaming de données, tels que la scalabilité, la haute disponibilité, la résilience aux pannes, et la faible latence. Kafka est également conçu pour gérer des volumes de données massifs en temps réel, ce qui est crucial pour de nombreuses applications de traitement de données en temps réel.