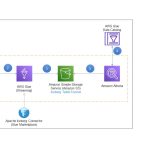
Amazon Redshift
Points abordés dans cet article
Mis à jour le 22 juin 2025
L’essentiel en un clin d’œil
Amazon Redshift
- Définition : entrepôt de données cloud d’AWS conçu pour analyser des volumes massifs de données rapidement.
- Architecture : traitement massivement parallèle (MPP), nœuds de calcul et de stockage répartis en cluster.
- Cas d’usage : BI, marketing, IoT, finance — pour exploiter les données à l’échelle du pétaoctet.
- Fonctionnalités clés : SQL, intégration BI (Power BI, Tableau), chiffrement, scalabilité, migration facilitée.
- Performance & coût : très rapide, stockage colonne, compression, tarification à l’usage & auto-scalable.
- Alternatives : BigQuery, Snowflake, Azure Synapse, IBM Cloud Pak — selon besoins techniques et cloud choisi.

De nos jours, les entreprises sont confrontées à une explosion des données. Les volumes de données à stocker, à surveiller et à analyser augmentent à une vitesse sans précédent, ce qui rend le travail avec des systèmes de stockage de données traditionnels de plus en plus difficile. Avec l’avènement du cloud computing, il est devenu évident que des solutions de stockage dans le cloud capables d’accélérer la demande croissante en matière de stockage et d’analyse de données sont nécessaires. C’est là qu’intervient Amazon Redshift.
Amazon Redshift est un produit de base de données dans le cloud conçu pour stocker et analyser des données à l’échelle du pétaoctet. Il est également utilisé pour les migrations à grande échelle. La solution basée sur PostgreSQL 8 est conçue pour se connecter à des clients SQL et des outils de business intelligence, ce qui rend les données disponibles aux utilisateurs en temps réel. Redshift offre des performances rapides et des requêtes efficaces qui aident les équipes à prendre des décisions commerciales éclairées. Dans cette introduction à Amazon Redshift, nous allons explorer les fonctionnalités de cette solution de stockage et d’analyse de données dans le cloud.
Qu’est-ce qu’Amazon Redshift ?
Dans ce chapitre, nous allons plonger plus en détail dans Amazon Redshift. Nous allons explorer ce qu’est Amazon Redshift, ses caractéristiques et ses avantages par rapport aux solutions de stockage traditionnelles. Nous verrons également comment Amazon Redshift utilise une architecture distribuée pour stocker et analyser des données à grande échelle dans le cloud.
Amazon Redshift est un service de base de données dans le cloud offert par Amazon Web Services (AWS). Il est conçu pour stocker et analyser des données à grande échelle à l’aide d’une architecture de base de données distribuée. Les données sont stockées dans des clusters de nœuds et peuvent être facilement accessibles via des outils de business intelligence ou des clients SQL. En tant que service de base de données dans le cloud, Amazon Redshift offre une évolutivité et une flexibilité exceptionnelles, ainsi qu’une sécurité et une conformité de haut niveau.
Les caractéristiques de Redshift
Voici les principales caractéristiques d’Amazon Redshift :
- Scalabilité : Amazon Redshift est conçu pour être hautement évolutif, ce qui signifie que les organisations peuvent facilement augmenter ou diminuer la taille de leur cluster en fonction de leurs besoins en matière de stockage et d’analyse de données.
- Performances élevées : Redshift offre des performances rapides grâce à l’utilisation d’une architecture de traitement massivement parallèle (MPP) et de stockage de données colonnes. Ces fonctionnalités permettent à Redshift de traiter rapidement les requêtes même sur de très grandes quantités de données.
- Sécurité : Redshift offre une sécurité de niveau entreprise avec une protection des données en transit et au repos, ainsi qu’un accès basé sur les rôles et la gestion des clés de chiffrement.
- Facilité d’utilisation : Amazon Redshift est facile à utiliser grâce à son interface conviviale qui permet aux utilisateurs de gérer leurs clusters de manière intuitive.
- Connectivité : Redshift est compatible avec de nombreux outils d’analyse et de business intelligence, tels que Tableau, Power BI, et bien d’autres, ce qui permet aux utilisateurs d’explorer et d’analyser les données stockées dans Redshift à l’aide de leurs outils préférés.
- Coût avantageux : Amazon Redshift offre un coût total de possession avantageux par rapport aux solutions de stockage de données traditionnelles, car il est basé sur un modèle de paiement à l’utilisation qui permet aux organisations de payer uniquement pour ce qu’elles utilisent.
Les alternatives
Il existe plusieurs alternatives ou équivalents à Amazon Redshift dans les autres services cloud. Voici quelques exemples :
- Google BigQuery : Google BigQuery est un service d’entreposage de données entièrement géré, conçu pour stocker et analyser de gros volumes de données en utilisant des requêtes SQL.
- Microsoft Azure Synapse Analytics : Microsoft Azure Synapse Analytics est un service d’analyse de données qui permet de stocker et de traiter de gros volumes de données à l’aide de technologies de traitement distribué, notamment Apache Spark et SQL.
- Snowflake : Snowflake est une plateforme d’analyse de données basée sur le cloud qui offre des performances élevées et une évolutivité automatique pour le stockage et l’analyse de données.
- IBM Cloud Pak for Data : IBM Cloud Pak for Data est une plateforme d’analyse de données qui permet de stocker, gérer et analyser des données à l’aide d’outils de business intelligence, d’apprentissage automatique et d’analyse prédictive.
Ces alternatives offrent des fonctionnalités similaires à Amazon Redshift et sont également des solutions cloud gérées qui permettent aux entreprises de stocker, gérer et analyser de gros volumes de données de manière évolutive et flexible.
Quand Amazon Redshift peut être utile?
Amazon Redshift est utile dans les cas où une entreprise doit stocker et analyser de grandes quantités de données, souvent des téraoctets ou des pétaoctets. Il est particulièrement utile pour les entreprises qui ont besoin de stocker des données structurées dans un format de base de données relationnelle.
Voici quelques exemples de cas d’utilisation courants pour Redshift :
- Business Intelligence (BI) : Redshift peut être utilisé pour stocker des données d’entreprise et les rendre facilement accessibles aux outils de BI. Les entreprises peuvent ainsi analyser rapidement des données volumineuses et complexes pour identifier des tendances, des modèles ou des anomalies.
- Marketing et analyse de données clients : Redshift peut être utilisé pour stocker et analyser les données clients, notamment les historiques d’achat, les comportements de navigation sur le site, les interactions sur les réseaux sociaux et les données démographiques. Les entreprises peuvent ainsi mieux comprendre leurs clients et personnaliser leurs offres en conséquence.
- Analyse de données IoT : Redshift peut être utilisé pour stocker et analyser les données générées par les appareils IoT, tels que les capteurs, les compteurs intelligents et les dispositifs de surveillance. Les entreprises peuvent ainsi identifier des modèles dans les données pour améliorer la maintenance prédictive, la gestion de la chaîne d’approvisionnement et la qualité des produits.
- Analyse financière : Redshift peut être utilisé pour stocker et analyser les données financières de l’entreprise, telles que les comptes clients, les comptes fournisseurs, les états financiers et les transactions. Les entreprises peuvent ainsi effectuer des analyses de rentabilité, des prévisions financières et des simulations de scénarios.
Redshift est utile pour toute entreprise qui a besoin de stocker et d’analyser de grandes quantités de données dans un environnement évolutif et flexible.
Architecture d’Amazon Redshift
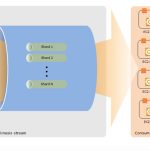
Amazon Redshift est basé sur une architecture de traitement massivement parallèle (MPP). Cela signifie que les tâches de traitement sont réparties sur plusieurs nœuds de traitement pour accélérer les performances.
Chaque cluster de Redshift se compose de plusieurs nœuds. Il y a deux types de nœuds dans Redshift : les nœuds de calcul et les nœuds de stockage. Les nœuds de calcul traitent les requêtes et renvoient les résultats au client. Les nœuds de stockage stockent les données et assurent la récupération et l’écriture de données à partir du disque.
Les différents types de nœuds dans Redshift sont :
- Les nœuds de calcul : ils sont utilisés pour effectuer les tâches de traitement et peuvent être configurés en différentes tailles en fonction des besoins de l’utilisateur. Les types de nœuds de calcul disponibles incluent dc2.large, dc2.8xlarge et ds2.xlarge.
- Les nœuds de stockage : ils stockent les données et fournissent des capacités de lecture/écriture pour les requêtes. Les types de nœuds de stockage disponibles incluent ds2.xlarge, ds2.8xlarge et dc1.large.
Les clusters dans Redshift fonctionnent en divisant les données en blocs et en distribuant ces blocs sur les nœuds de stockage. Les blocs de données sont également répliqués pour garantir la disponibilité et la tolérance aux pannes.
Lorsqu’une requête est soumise à Redshift, le nœud de calcul principal divise la requête en plusieurs sous-tâches et les distribue à tous les nœuds de calcul disponibles. Chaque nœud de calcul exécute sa partie de la tâche et renvoie les résultats au nœud de calcul principal pour agrégation. Enfin, le nœud de calcul principal renvoie le résultat final au client.
L’architecture de Redshift utilise une approche de traitement massivement parallèle pour accélérer les performances de traitement et de requête. Les nœuds de calcul et de stockage sont configurés pour répondre aux besoins spécifiques de l’utilisateur, et les clusters sont conçus pour garantir la disponibilité et la tolérance aux pannes.
Fonctionnalités d’Amazon Redshift
Amazon Redshift est une solution de stockage et d’analyse de données puissante qui offre plusieurs fonctionnalités utiles aux utilisateurs. Voici les principales fonctionnalités d’Amazon Redshift :
- Stockage et récupération des données : Amazon Redshift offre une capacité de stockage évolutive allant de quelques gigaoctets à plusieurs pétaoctets, avec une latence très faible pour la récupération de données. Il permet également aux utilisateurs de stocker différents types de données, tels que des données structurées, semi-structurées et non structurées.
- Analyse des données : Redshift prend en charge les outils d’analyse des données tels que SQL et les outils de Business Intelligence, tels que Tableau, MicroStrategy, QlikView, etc. Il permet aux utilisateurs d’interroger de grandes quantités de données et d’obtenir des résultats rapides.
- Migration de données : Redshift peut être utilisé pour migrer les données d’autres sources de données telles que Oracle, MySQL, SQL Server, etc. Il prend également en charge les outils de migration de données tels que AWS Database Migration Service pour migrer les données depuis les bases de données hébergées sur site.
- Sécurité et conformité : Redshift offre une sécurité de bout en bout et prend en charge plusieurs fonctionnalités de sécurité, telles que la cryptographie, la gestion des clés, l’authentification, etc. Il prend également en charge les normes de conformité telles que PCI DSS, HIPAA, SOC, etc.
Performance et coût d’utilisation d’Amazon Redshift
- Les performances de Redshift : Amazon Redshift est connu pour sa rapidité et sa capacité à traiter des quantités massives de données en peu de temps. Il utilise des méthodes de stockage de données en colonnes, des clusters de nœuds et une architecture MPP (Massively Parallel Processing) pour offrir des performances de requête élevées. De plus, la distribution des données entre les nœuds de calcul et la compression de données contribuent également à accélérer les performances.
- Les coûts d’utilisation de Redshift : Amazon Redshift est un service payant et ses coûts d’utilisation dépendent de plusieurs facteurs tels que le type de nœud, le nombre de nœuds, le stockage utilisé, les frais de transfert de données, etc. Cependant, il est moins cher que les solutions de stockage traditionnelles, car il élimine la nécessité de frais initiaux pour l’achat et la maintenance de matériel.
- La scalabilité de Redshift : Amazon Redshift est très évolutif et offre une capacité de stockage évolutive allant de quelques gigaoctets à plusieurs pétaoctets. Les utilisateurs peuvent facilement ajouter ou supprimer des nœuds de calcul en fonction de leurs besoins de capacité et de performance, et ne paient que pour la capacité qu’ils utilisent réellement. De plus, la fonctionnalité de mise à l’échelle automatique permet à Redshift de s’ajuster automatiquement aux fluctuations des demandes de données.
Comment utiliser Amazon Redshift ?
- Prérequis pour utiliser Redshift
Avant de pouvoir utiliser Amazon Redshift, vous devez avoir un compte AWS actif et accéder à la console AWS. Vous devez également disposer des autorisations nécessaires pour créer et gérer des clusters Redshift, ainsi que pour accéder aux ressources AWS telles que S3. - Création d’un cluster Redshift
La création d’un cluster Redshift est simple et peut être effectuée à partir de la console AWS. Vous devrez choisir le type de nœud, le nombre de nœuds, l’emplacement du cluster, le nom de l’utilisateur principal et le mot de passe. Vous pourrez également choisir de configurer la sécurité, les autorisations d’accès et les paramètres de réseau. Une fois le cluster créé, vous pourrez vous connecter à l’aide d’un client SQL ou de la console AWS. - Configuration des autorisations d’accès
Pour accéder à un cluster Redshift, vous devez configurer les autorisations d’accès en créant des groupes de sécurité de cluster et en définissant les autorisations pour ces groupes. Vous pouvez accorder des autorisations à des utilisateurs ou à des groupes d’utilisateurs pour accéder à des bases de données spécifiques ou pour effectuer des actions spécifiques telles que la création de tables ou l’exécution de requêtes. - Connexion au cluster Redshift
Une fois que vous avez créé un cluster Redshift et configuré les autorisations d’accès, vous pouvez vous connecter à l’aide d’un client SQL ou de la console AWS. Vous devrez utiliser l’adresse du point de terminaison du cluster et les informations d’identification de l’utilisateur principal que vous avez définies lors de la création du cluster. À partir de là, vous pouvez créer des tables, importer des données et exécuter des requêtes pour analyser vos données.
Conclusion
Amazon Redshift est une solution de stockage et d’analyse de données dans le cloud qui a rapidement gagné en popularité ces dernières années. Sa capacité à stocker et traiter de grands volumes de données de manière rapide et efficace en fait une option attrayante pour les entreprises qui cherchent à améliorer leur analyse de données et leur prise de décision.
Dans ce guide, nous avons examiné les caractéristiques et les avantages d’Amazon Redshift par rapport aux solutions de stockage traditionnelles, ainsi que son architecture, ses fonctionnalités et ses performances. Nous avons également expliqué comment utiliser Amazon Redshift, de la création d’un cluster à la connexion à celui-ci.
En fin de compte, Amazon Redshift est un outil puissant pour le stockage et l’analyse de données dans le cloud, offrant des performances rapides et une évolutivité facile, tout en étant simple à utiliser. Il est clair que cette solution continuera d’être une option attrayante pour les entreprises à mesure que leurs besoins en matière de stockage et d’analyse de données continuent de croître.
Foire aux questions
Dans cette section, nous répondrons à quelques-unes des questions les plus courantes sur Amazon Redshift. Ces questions aborderont des sujets tels que la sécurité, les performances, les coûts et l’utilisation de Redshift.
Quels types de données Amazon Redshift peut-il stocker ?
Amazon Redshift peut stocker une variété de types de données, notamment des données structurées et semi-structurées, telles que les données de base de données relationnelle, les données JSON, les fichiers CSV et les fichiers de log.
Comment fonctionne la tarification d’Amazon Redshift ?
La tarification d’Amazon Redshift est basée sur le type de nœud utilisé, le nombre de nœuds, la durée d’utilisation et la quantité de données stockées. Les clients paient également des frais de transfert de données pour les données entrant et sortant de Redshift.
Comment Amazon Redshift traite-t-il de grandes quantités de données ?
Amazon Redshift utilise une architecture de traitement massivement parallèle (MPP) qui divise les données en blocs et les distribue sur plusieurs nœuds pour un traitement simultané. Cela permet à Redshift de traiter de grandes quantités de données rapidement.
Comment sécuriser les données stockées dans Amazon Redshift ?
Amazon Redshift offre plusieurs options de sécurité, notamment la connexion SSL pour le transit de données, le cryptage des données au repos, les groupes de sécurité pour le contrôle d’accès et la gestion des clés de chiffrement.
Comment effectuer une migration de données vers Amazon Redshift ?
Amazon Redshift offre plusieurs options pour migrer des données, notamment l’importation de données à partir de fichiers CSV, la connexion à des bases de données externes via des liens ODBC ou JDBC, et l’utilisation de services tiers pour la migration de données.
Quels sont les outils de BI compatibles avec Amazon Redshift ?
Amazon Redshift est compatible avec de nombreux outils de business intelligence, notamment Tableau, Power BI, MicroStrategy, Looker, Domo et de nombreux autres.
Comment surveiller les performances d’Amazon Redshift ?
Amazon Redshift offre plusieurs options pour surveiller les performances, notamment des outils intégrés tels que l’observateur de performances Redshift et des services tiers tels que Sumo Logic, CloudWatch et Dynatrace. Ces outils permettent de surveiller les requêtes, l’utilisation des ressources et les temps de réponse.