Les étapes de collecte de données
Points abordés dans cet article
Mis à jour le 22 juin 2025
📥 Collecte de données – Résumé pratique
- Objectif : Collecter des données fiables, valides et pertinentes pour garantir des analyses précises et décisionnelles.
- 5 étapes clés :
- Définition des objectifs : questions de recherche, types de données, critères de qualité.
- Sélection des sources : données internes, sondages, APIs, réseaux sociaux, bases externes fiables.
- Collecte : mise en œuvre des méthodes adaptées (enquêtes, scraping, transactions, etc.).
- Nettoyage : suppression des doublons, correction des erreurs, vérification de la cohérence.
- Préparation : transformation, filtrage, normalisation et échantillonnage des données.
- Outils populaires : Python (Pandas, Scrapy), SQL, Tableau, Power BI, SPSS, Talend, OpenRefine.
- Bonnes pratiques : garantir l’éthique (RGPD), protéger la vie privée, former les collecteurs, planifier les contrôles qualité.
- Erreurs à éviter : collecte biaisée, sources non fiables, objectifs flous, absence de validation ou de nettoyage.

La collecte de données est une étape essentielle de tout processus d’analyse de données. En effet, la qualité des données collectées détermine la qualité de l’analyse qui en découle. C’est pourquoi il est important de comprendre les différentes étapes de la collecte de données pour garantir la qualité des résultats de l’analyse.
Cet article a pour objectif d’expliquer les différentes étapes de la collecte de données, y compris la définition des objectifs de collecte, la sélection des sources de données, la collecte de données, le nettoyage et la préparation des données. En comprenant ces différentes étapes, les analystes de données peuvent améliorer la qualité de leurs données et ainsi obtenir des résultats d’analyse plus précis et pertinents.
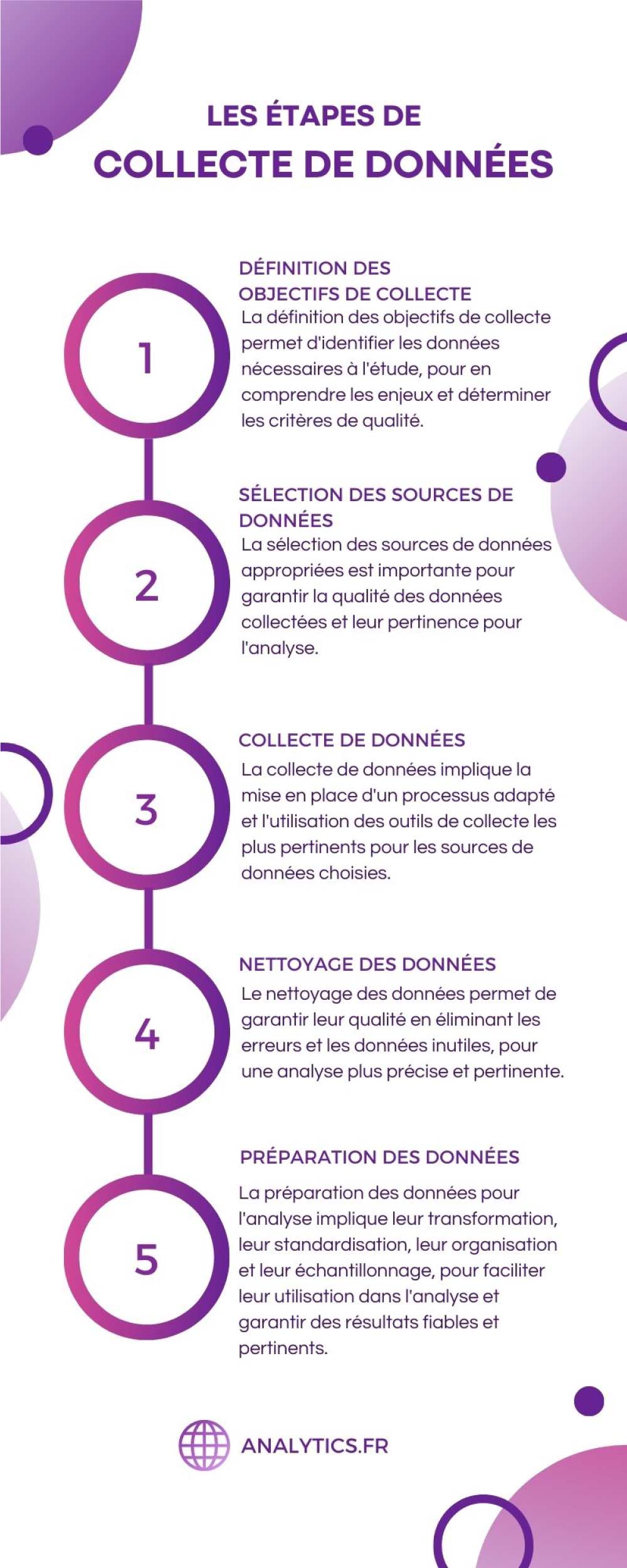
1. Définition des objectifs de collecte
Comprendre les objectifs de l’étude
La première étape de la collecte de données consiste à comprendre les objectifs de l’étude. Cela implique de définir les questions de recherche que l’analyse de données devra répondre. Les objectifs de l’étude peuvent être très variés, allant de la compréhension des habitudes de consommation des clients à l’analyse de la performance des employés.
Une fois que les questions de recherche ont été définies, il est important d’identifier les types de données nécessaires pour y répondre. Par exemple, pour comprendre les habitudes de consommation des clients, il peut être nécessaire de collecter des données sur leurs achats, leur âge, leur sexe, leur lieu de résidence, etc.
Enfin, il est important de déterminer les critères de qualité des données, tels que la fiabilité, la validité et la pertinence. Les critères de qualité aideront à évaluer la qualité des données collectées et à garantir qu’elles répondent aux objectifs de l’étude.
Identifier les types de données nécessaires
Pour identifier les types de données nécessaires, il est important de revenir aux questions de recherche qui ont été définies. Les données nécessaires dépendent de l’objectif de l’étude.
Par exemple, si l’objectif de l’étude est de comprendre les habitudes de consommation des clients, les données nécessaires pourraient inclure :
- Les transactions d’achat (date, heure, produit acheté, montant, etc.)
- Les informations démographiques (âge, sexe, lieu de résidence, etc.)
- Les données comportementales (fréquence d’achat, produits achetés ensemble, etc.)
- Les commentaires ou les évaluations laissés par les clients sur les produits ou les services
En général, les types de données nécessaires pour répondre à une question de recherche sont déterminés en fonction de la nature de la question et des hypothèses de l’étude. Il est important de s’assurer que les données collectées répondent aux questions de recherche et qu’elles sont de qualité suffisante pour l’analyse.
Déterminer les critères de qualité des données
Déterminer les critères de qualité des données est une étape cruciale de la collecte de données. Les critères de qualité permettent d’évaluer la qualité des données collectées et de s’assurer qu’elles sont fiables, valides et pertinentes pour répondre aux questions de recherche.
Voici quelques critères de qualité des données :
- Fiabilité : Les données doivent être cohérentes et reproductibles. Cela signifie que si les mêmes données sont collectées plusieurs fois, elles doivent donner les mêmes résultats.
- Validité : Les données doivent mesurer ce qu’elles sont censées mesurer. Par exemple, si vous collectez des données sur le poids des gens, les mesures doivent être précises et fiables.
- Pertinence : Les données doivent être pertinentes pour répondre aux questions de recherche. Les données qui ne sont pas pertinentes peuvent biaiser les résultats de l’analyse.
- Exhaustivité : Les données doivent couvrir toutes les variables nécessaires à l’étude. Si des variables importantes sont manquantes, cela peut biaiser les résultats de l’analyse.
- Consistance : Les données doivent être cohérentes dans leur format et leur structure. Cela facilite l’analyse et la compréhension des données.
- Précision : Les données doivent être précises et exactes. Si les données sont imprécises, cela peut biaiser les résultats de l’analyse.
En déterminant les critères de qualité des données, les analystes de données peuvent évaluer la qualité des données collectées et s’assurer qu’elles sont appropriées pour répondre aux questions de recherche.
2. Sélection des sources de données
Identifier les sources de données potentielles
Une fois les objectifs de l’étude et les types de données nécessaires identifiés, la prochaine étape est d’identifier les sources de données potentielles. Les sources de données peuvent être internes à l’entreprise ou externes, telles que des sources gouvernementales, des enquêtes publiques, des données en libre accès sur le web ou des bases de données commerciales.
Voici quelques exemples de sources de données potentielles :
- Bases de données internes : Les bases de données internes de l’entreprise contiennent souvent des données sur les clients, les ventes, les stocks, les transactions, etc. Ces données peuvent être extraites et utilisées pour l’analyse.
- Données de médias sociaux : Les médias sociaux peuvent fournir des données sur les interactions des clients avec l’entreprise, les commentaires et les évaluations.
- Données de recherche en ligne : Les recherches en ligne peuvent fournir des données sur les tendances de marché, les prix, les concurrents, etc.
- Enquêtes et sondages : Les enquêtes et les sondages peuvent être utilisés pour collecter des données directement auprès des clients ou des employés.
- Données gouvernementales : Les données gouvernementales peuvent être utilisées pour étudier les tendances économiques, les données démographiques, les statistiques de santé, etc.
Il est important de sélectionner les sources de données qui répondent aux critères de qualité définis précédemment et qui sont les plus pertinentes pour répondre aux questions de recherche.
Évaluer la qualité et la pertinence des sources de données
Une fois les sources de données potentielles identifiées, il est important d’évaluer leur qualité et leur pertinence pour répondre aux questions de recherche.
Voici quelques critères à prendre en compte lors de l’évaluation de la qualité et de la pertinence des sources de données :
- Fiabilité : La source de données est-elle fiable et a-t-elle été vérifiée pour assurer sa précision et sa cohérence ?
- Validité : La source de données mesure-t-elle exactement ce qu’elle est censée mesurer ? Les mesures sont-elles fiables et précises ?
- Pertinence : La source de données contient-elle les variables nécessaires pour répondre aux questions de recherche ?
- Échantillonnage : La taille et la représentativité de l’échantillon sont-elles suffisantes pour que les données soient significatives ?
- Cohérence : Les données sont-elles cohérentes en termes de format, de structure et d’échelle de mesure ?
- Disponibilité : Les données sont-elles disponibles et accessibles pour l’analyse ?
- Coût : Le coût de l’acquisition des données est-il justifié par rapport à la valeur qu’elles apporteront à l’analyse ?
En évaluant la qualité et la pertinence des sources de données, les analystes peuvent sélectionner les sources de données les plus appropriées pour répondre aux questions de recherche. Cela permettra d’améliorer la qualité et la précision de l’analyse de données.
Sélectionner les sources de données finales
Une fois que les sources de données ont été évaluées en termes de qualité et de pertinence, la prochaine étape consiste à sélectionner les sources de données finales pour l’analyse.
Voici quelques critères à prendre en compte lors de la sélection des sources de données finales :
- Pertinence : Les sources de données finales répondent-elles aux questions de recherche et contiennent-elles les variables nécessaires ?
- Qualité : Les sources de données finales ont-elles été évaluées et ont-elles été jugées de bonne qualité ?
- Complétude : Les sources de données finales couvrent-elles tous les aspects nécessaires de l’étude et fournissent-elles une image complète ?
- Disponibilité : Les sources de données finales sont-elles disponibles pour l’analyse ?
- Coût : Le coût de l’acquisition des sources de données finales est-il justifié par rapport à la valeur qu’elles apporteront à l’analyse ?
Il est important de sélectionner les sources de données finales en fonction des critères établis pour garantir la qualité et la pertinence des données pour l’analyse. Les sources de données finales sélectionnées doivent fournir une image complète et précise des variables étudiées, permettant ainsi de répondre aux questions de recherche et d’obtenir des résultats d’analyse fiables et significatifs.
3. Collecte de données
Concevoir le processus de collecte de données
Une fois les sources de données finales sélectionnées, la prochaine étape consiste à concevoir le processus de collecte de données. Cette étape implique de définir les méthodes de collecte de données les plus appropriées pour chaque source de données.
Voici quelques méthodes de collecte de données courantes :
- Collecte de données en ligne : Les enquêtes en ligne et les formulaires peuvent être utilisés pour collecter des données auprès de personnes ou d’entreprises. Les données collectées peuvent être facilement stockées dans des bases de données et sont faciles à analyser.
- Collecte de données sur le terrain : Les enquêtes et les observations sur le terrain peuvent être utilisées pour collecter des données auprès des clients ou pour collecter des données sur le terrain, telles que des mesures environnementales.
- Données de transaction : Les données de transaction peuvent être collectées à partir des systèmes de point de vente, des systèmes de paiement ou des bases de données financières. Ces données peuvent être utilisées pour comprendre les habitudes d’achat des clients.
- Données de médias sociaux : Les données de médias sociaux peuvent être collectées à l’aide d’outils d’analyse de médias sociaux pour comprendre les opinions et les sentiments des clients.
Il est important de choisir les méthodes de collecte de données les plus appropriées pour chaque source de données. Les méthodes de collecte doivent être efficaces et fiables pour garantir la qualité des données collectées.
Collecter les données selon les méthodes choisies
Une fois que les méthodes de collecte de données ont été choisies, la collecte de données proprement dite peut commencer. Cette étape consiste à collecter les données selon les méthodes choisies.
Voici quelques bonnes pratiques à suivre lors de la collecte de données :
- Établir un plan de collecte de données : Il est important de définir un plan de collecte de données qui inclut les étapes de collecte, les ressources nécessaires, les délais, etc.
- Former le personnel : Si le personnel est impliqué dans la collecte de données, il est important de les former aux méthodes de collecte de données et de leur fournir des instructions claires.
- Utiliser des outils de collecte de données appropriés : Les outils de collecte de données doivent être adaptés aux méthodes de collecte de données choisies. Par exemple, des questionnaires en ligne peuvent être utilisés pour la collecte de données en ligne.
- Assurer la qualité des données collectées : Il est important de vérifier la qualité des données collectées en utilisant des contrôles de qualité appropriés, tels que la vérification des données ou la relecture des questionnaires.
- Protéger la vie privée des personnes : Si des données personnelles sont collectées, il est important de protéger la vie privée des personnes en conformité avec les lois et réglementations en vigueur.
En suivant ces bonnes pratiques, les analystes de données peuvent garantir la qualité des données collectées et obtenir des résultats d’analyse plus précis et pertinents.
Les outils de collecte de données appropriés: les plus populaires
l existe plusieurs outils de collecte de données disponibles pour chaque méthode de collecte de données. Voici quelques-uns des outils de collecte de données les plus populaires :
- Enquêtes en ligne : Google Forms, SurveyMonkey, Typeform, Qualtrics
- Collecte de données sur le terrain : ODK Collect, SurveyCTO, KoboToolbox, FormHub
- Données de transaction : Excel, MySQL, Salesforce, QuickBooks
- Données de médias sociaux : Hootsuite Insights, Brandwatch, Sprout Social, Meltwater
Il est important de choisir l’outil de collecte de données approprié en fonction des besoins de l’étude et des exigences de collecte de données. Les outils de collecte de données doivent être efficaces, fiables et sécurisés pour garantir la qualité des données collectées.
Voici quelques exemples de langages de programmation et de bibliothèques couramment utilisés pour la collecte et le traitement de données :
- Python : Python est un langage de programmation populaire utilisé pour l’analyse de données. Les bibliothèques couramment utilisées pour la collecte et le traitement de données incluent Pandas, NumPy, Beautiful Soup, Requests, Scrapy, et Selenium.
- R : R est un autre langage de programmation couramment utilisé pour l’analyse de données. Les bibliothèques couramment utilisées pour la collecte et le traitement de données incluent dplyr, tidyr, readr, rvest, httr, et RSelenium.
- SQL : SQL est un langage de requête de base de données couramment utilisé pour la collecte et l’organisation de données. Les systèmes de gestion de bases de données couramment utilisés pour la collecte de données incluent MySQL, PostgreSQL, et Oracle.
- API : Les API (Application Programming Interface) sont couramment utilisées pour la collecte de données à partir de services web. Les bibliothèques couramment utilisées pour la collecte de données API incluent Requests, Tweepy, et PyGithub pour Python, et httr et jsonlite pour R.
Ces outils techniques sont utiles pour la collecte de données en vrac ou pour l’automatisation de tâches de collecte de données, qui peuvent être utilisées dans des projets d’analyse de données.
il existe également des logiciels populaires pour la collecte de données, tels que :
- Web scraping : Le web scraping consiste à extraire des données à partir de sites web. Les logiciels populaires de web scraping incluent BeautifulSoup, Scrapy, et Selenium pour Python, et rvest pour R.
- Tableau : Tableau est un logiciel de visualisation de données couramment utilisé pour collecter, préparer et analyser des données à partir de diverses sources.
- Power BI : Power BI est un autre logiciel de visualisation de données qui permet de collecter, préparer et analyser des données à partir de diverses sources.
- SAS : SAS est un logiciel de traitement de données couramment utilisé pour la collecte, la préparation et l’analyse de données dans les entreprises.
- IBM SPSS : IBM SPSS est un autre logiciel de traitement de données couramment utilisé pour la collecte, la préparation et l’analyse de données.
Il est important de choisir les outils et les logiciels les plus appropriés en fonction des besoins de l’étude et des exigences de collecte de données. Les outils doivent être efficaces, fiables et sécurisés pour garantir la qualité des données collectées.
Vérifier la qualité des données collectées
La vérification de la qualité des données collectées est une étape essentielle pour garantir que les données sont précises, complètes et cohérentes. Voici quelques techniques courantes pour vérifier la qualité des données collectées :
- Vérification des données manquantes : Vérifiez s’il y a des données manquantes ou incomplètes. Les données manquantes peuvent être un problème important, car elles peuvent fausser les résultats de l’analyse.
- Détection des erreurs de saisie de données : Vérifiez les erreurs de saisie de données, telles que les erreurs de frappe et les incohérences dans les formats de données.
- Contrôle des doublons : Vérifiez si des doublons existent dans les données. Les doublons peuvent se produire en raison de la collecte de données redondantes ou de la saisie de données multiples pour la même personne ou la même entité.
- Vérification des données aberrantes : Vérifiez s’il y a des données aberrantes ou des valeurs extrêmes qui sont susceptibles de fausser les résultats de l’analyse.
- Vérification de la cohérence : Vérifiez si les données sont cohérentes avec les hypothèses et les attentes de l’analyse.
- Vérification de la qualité des sources de données : Vérifiez la qualité et la fiabilité des sources de données utilisées pour la collecte.
Ces techniques permettent de garantir la qualité des données collectées et d’identifier rapidement les erreurs ou les problèmes de données. En cas de problèmes, les analystes peuvent prendre des mesures correctives pour améliorer la qualité des données.
4. Nettoyage des données
Identifier et corriger les erreurs de données
Il existe plusieurs méthodes pour identifier et corriger les erreurs de données, que ce soit dans le cloud ou pas dans le cloud. Voici quelques-unes des méthodes couramment utilisées :
- Vérification manuelle : La vérification manuelle consiste à examiner les données à la recherche d’erreurs en utilisant des outils de traitement de texte, des feuilles de calcul ou des logiciels spécialisés. Cette méthode est relativement simple, mais elle peut prendre beaucoup de temps pour des ensembles de données importants.
- Statistiques descriptives : Les statistiques descriptives peuvent être utilisées pour identifier les valeurs aberrantes ou les incohérences dans les données. Cette méthode implique l’utilisation de moyennes, de médianes, de modes et d’autres statistiques pour détecter les erreurs de données.
- Méthodes de machine learning : Les méthodes de machine learning, telles que les arbres de décision et la régression, peuvent être utilisées pour identifier les erreurs de données en se basant sur des modèles prédictifs. Cette méthode est efficace pour traiter des ensembles de données importants et peut être utilisée dans le cloud.
- Nettoyage de données automatique : Les outils de nettoyage de données automatique peuvent être utilisés pour identifier et corriger les erreurs de données. Ces outils sont souvent basés sur des algorithmes de machine learning et peuvent être exécutés dans le cloud ou sur des ordinateurs locaux.
- Recodage des données : Le recodage des données consiste à modifier les valeurs de données en utilisant des règles prédéfinies pour corriger les erreurs de données. Cette méthode peut être utilisée pour corriger les erreurs de typographie, de formatage ou de codage.
Ces méthodes peuvent être utilisées individuellement ou combinées pour identifier et corriger les erreurs de données. Il est important de choisir les méthodes les plus appropriées en fonction des besoins de l’étude et des caractéristiques de l’ensemble de données.
voici quelques exemples de logiciels ou méthodes les plus populaires pour identifier et corriger les erreurs de données :
- OpenRefine : OpenRefine est un outil de nettoyage de données open source qui permet d’explorer, de nettoyer et de transformer de grands ensembles de données. Il utilise des algorithmes de clustering pour identifier les erreurs de données et permet de les corriger manuellement ou automatiquement.
- Trifacta : Trifacta est un outil de nettoyage de données qui utilise l’apprentissage automatique pour identifier les erreurs de données et propose des suggestions de correction. Il peut être utilisé pour nettoyer et préparer des données structurées et non structurées.
- Talend : Talend est un outil d’intégration de données qui peut être utilisé pour identifier les erreurs de données et les corriger. Il peut également être utilisé pour nettoyer les données, les fusionner, les transformer et les enrichir.
- Python : Python est un langage de programmation populaire qui offre de nombreuses bibliothèques pour le nettoyage de données, telles que Pandas, NumPy et SciPy. Ces bibliothèques peuvent être utilisées pour identifier et corriger les erreurs de données, ainsi que pour effectuer d’autres tâches de prétraitement de données.
- SQL : SQL est un langage de requête de base de données couramment utilisé pour nettoyer et préparer des données. Les fonctions de SQL, telles que DISTINCT, GROUP BY et ORDER BY, peuvent être utilisées pour identifier les erreurs de données et les corriger.
Ces outils et méthodes peuvent aider à identifier et à corriger efficacement les erreurs de données, ce qui peut améliorer la qualité et la fiabilité des résultats d’analyse. Il est important de choisir les outils et les méthodes les plus appropriés en fonction des besoins de l’étude et des caractéristiques de l’ensemble de données.
Éliminer les données dupliquées ou inutiles et vérifier la cohérence et la précision des données
Une fois que les erreurs de données ont été identifiées et corrigées, il est important d’éliminer les données dupliquées ou inutiles afin de simplifier et d’alléger l’ensemble de données. Les données dupliquées ou inutiles peuvent fausser les résultats d’analyse et entraîner une surcharge de stockage de données. Par conséquent, il est important d’éliminer ces données avant de poursuivre le traitement de l’ensemble de données.
En outre, il est essentiel de vérifier la cohérence et la précision des données avant d’effectuer une analyse. La vérification de la cohérence des données implique de s’assurer que les données sont logiques et conformes aux attentes de l’étude. Par exemple, si l’étude porte sur la santé des patients, il est important de s’assurer que les données de santé des patients sont cohérentes avec les normes médicales en vigueur. La vérification de la précision des données implique de s’assurer que les données sont exactes et qu’elles reflètent la réalité.
Pour garantir la cohérence et la précision des données, il est possible de comparer les données avec d’autres sources, de réaliser des analyses statistiques pour détecter les anomalies et de vérifier la qualité des données auprès de professionnels de l’industrie concernée. Il est également possible de recourir à des algorithmes d’apprentissage automatique pour effectuer une analyse prédictive et détecter les erreurs potentielles.
En somme, éliminer les données dupliquées ou inutiles et vérifier la cohérence et la précision des données sont des étapes importantes pour garantir la qualité des données et obtenir des résultats d’analyse précis et pertinents.
5. Préparation des données
La préparation des données pour l’analyse est une étape essentielle pour garantir la qualité des résultats d’analyse. Voici quelques étapes courantes pour préparer les données pour l’analyse :
- Création de sous-ensembles de données : Il peut être utile de créer des sous-ensembles de données en fonction de critères spécifiques pour faciliter l’analyse. Par exemple, il peut être intéressant de créer un sous-ensemble de données en fonction de l’emplacement géographique ou de la période de temps pour faciliter l’analyse.
- Transformation des données : La transformation des données peut être utile pour faciliter l’analyse. Cette étape peut inclure la normalisation des données, la conversion de données en différents formats, ou la création de variables supplémentaires à partir des données existantes pour faciliter l’analyse.
- Sélection des variables pertinentes : La sélection des variables pertinentes peut aider à réduire le bruit dans les données et à faciliter l’analyse. Cette étape implique la sélection des variables les plus importantes pour l’analyse, en fonction des objectifs de l’étude et des hypothèses de recherche.
- Échantillonnage de données : L’échantillonnage de données peut être utilisé pour sélectionner une partie de l’ensemble de données pour l’analyse. Cette méthode peut être utilisée lorsque l’ensemble de données est trop volumineux pour être analysé dans son intégralité.
En résumé, la préparation des données pour l’analyse est une étape importante pour garantir la qualité des résultats d’analyse. Cette étape implique la création de sous-ensembles de données, la transformation des données, la sélection des variables pertinentes, et l’échantillonnage de données. Ces étapes aident à faciliter l’analyse et à réduire le bruit dans les données, ce qui permet d’obtenir des résultats d’analyse plus précis et plus pertinents.
Conclusion
En résumé, la collecte de données est une étape essentielle pour réaliser une analyse précise et pertinente. Voici un récapitulatif des étapes clés de la collecte de données :
- Comprendre les objectifs de l’étude et identifier les types de données nécessaires.
- Déterminer les critères de qualité des données et identifier les sources de données potentielles.
- Évaluer la qualité et la pertinence des sources de données et sélectionner les sources de données finales.
- Concevoir le processus de collecte de données et collecter les données selon les méthodes choisies.
- Vérifier la qualité des données collectées et identifier et corriger les erreurs de données.
- Éliminer les données dupliquées ou inutiles, vérifier la cohérence et la précision des données, et préparer les données pour l’analyse.
Il est important de souligner l’importance de la collecte de données de qualité pour garantir des résultats d’analyse précis et pertinents. La qualité des données est essentielle pour garantir que les résultats d’analyse reflètent la réalité et sont utiles pour la prise de décision. En effet, des données de mauvaise qualité peuvent fausser les résultats d’analyse et entraîner des conclusions erronées. Par conséquent, il est important de suivre des étapes claires et précises pour collecter, vérifier, nettoyer et préparer les données pour l’analyse, afin de garantir des résultats d’analyse de qualité et utiles.
Foire aux questions sur la collecte de données
Qu’est-ce que la collecte de données ?
La collecte de données est le processus de rassemblement d’informations pertinentes pour une étude ou une analyse. Elle peut être réalisée à partir de diverses sources, telles que des enquêtes, des sondages, des expériences, des bases de données, etc.
Pourquoi la collecte de données est-elle importante ?
La collecte de données est importante car elle fournit des informations de base pour une étude ou une analyse. Elle permet de prendre des décisions éclairées et de comprendre les tendances et les modèles qui sous-tendent les phénomènes observés.
Quels sont les types de données que l’on peut collecter ?
Les types de données que l’on peut collecter incluent des données quantitatives (mesurables numériquement) et des données qualitatives (non numériques, telles que les opinions, les attitudes et les comportements).
Comment peut-on garantir la qualité des données collectées ?
La qualité des données collectées peut être garantie en suivant des étapes claires et précises pour collecter, vérifier, nettoyer et préparer les données pour l’analyse. Il est également important de vérifier la cohérence et la précision des données, d’éliminer les données dupliquées ou inutiles, et de sélectionner les variables les plus pertinentes pour l’analyse.
Comment peut-on collecter des données de manière éthique ?
La collecte de données doit être effectuée de manière éthique en respectant la confidentialité et l’intimité des participants, en obtenant le consentement éclairé des participants, et en garantissant que les données collectées sont utilisées uniquement à des fins éthiques.
Comment peut-on choisir les sources de données appropriées pour une étude ?
Les sources de données appropriées pour une étude doivent être choisies en fonction des objectifs de l’étude, des critères de qualité des données et des types de données nécessaires. Il est également important d’évaluer la qualité et la pertinence des sources de données avant de les sélectionner.
Comment peut-on préparer les données pour l’analyse ?
Les données peuvent être préparées pour l’analyse en créant des sous-ensembles de données en fonction de critères spécifiques, en transformant les données pour les rendre utilisables, en standardisant les données pour les rendre comparables, en nettoyant les données pour éliminer les erreurs, et en sélectionnant les variables les plus pertinentes pour l’analyse.
Quels sont les outils et les méthodes couramment utilisés pour nettoyer et préparer les données ?
Les outils et les méthodes couramment utilisés pour nettoyer et préparer les données incluent des logiciels d’analyse de données tels que Python, SQL, OpenRefine, Trifacta et Talend. Ces outils peuvent être utilisés pour identifier et corriger les erreurs de données, standardiser les données, éliminer les données dupliquées ou inutiles, et préparer les données pour l’analyse.
Quelles sont les erreurs courantes à éviter lors de la collecte de données ?
Les erreurs courantes à éviter lors de la collecte de données incluent le manque de clarté sur les objectifs de l’étude, la sélection de sources de données inappropriées, la collecte de données biaisées, la saisie incorrecte des données, le manque de vérification de la qualité des données, et la mauvaise préparation des données pour l’analyse.
Comment peut-on garantir la fiabilité et la validité des données collectées ?
La fiabilité et la validité des données collectées peuvent être garanties en utilisant des méthodes standardisées pour collecter et analyser les données, en vérifiant la qualité des données collectées, en évitant les biais de sélection et en utilisant des techniques d’échantillonnage appropriées.
Comment peut-on utiliser les résultats d’une analyse de données pour prendre des décisions ?
Les résultats d’une analyse de données peuvent être utilisés pour prendre des décisions en fournissant des informations précieuses sur les tendances et les modèles qui sous-tendent les phénomènes observés. Les résultats d’analyse peuvent être utilisés pour identifier les problèmes, les opportunités et les solutions potentielles, et pour aider à prendre des décisions plus éclairées et plus efficaces.
Articles similaires
![analyse de données avec excel]()
Business Intelligence sous Excel avec Power Query, Power Pivot et Power Map
![utilitaire analyse excel]()
L’utilitaire d'analyse de données d'Excel
![tendances analyse de donnees]()
10 tendances sur l'analyse de données pour 2023
![trier filtrer excel]()
Comment trier et filtrer les données avec Excel
![analyste de données analysant des graphiques et tableaux de bord data analytics]()
Guide complet de l'analyse de données : feuilles de calcul, fonctions essentielles, visualisation et nature des données
![data driven]()
Comment les données peuvent aider les entreprises?